Giới thiệu Gemini 2.5 Flash
Gemini 2.5 Flash là mô hình suy luận hoàn toàn kết hợp đầu tiên của chúng tôi, cho phép các nhà phát triển bật hoặc tắt khả năng suy nghĩ.
- 6 min read

Bắt đầu xây dựng với Gemini 2.5 Flash
Gemini 2.5 Flash hiện đang ở giai đoạn xem trước, cung cấp khả năng suy luận được cải thiện đồng thời ưu tiên tốc độ và hiệu quả chi phí cho các nhà phát triển.
Ngày 17 tháng 4 năm 2025
Tulsee Doshi, Giám đốc Quản lý Sản phẩm, Gemini
Hôm nay, chúng tôi đang triển khai phiên bản đầu tiên của Gemini 2.5 Flash ở chế độ xem trước thông qua Gemini API qua Google AI Studio và Vertex AI. Dựa trên nền tảng phổ biến của 2.0 Flash, phiên bản mới này mang đến một nâng cấp lớn về khả năng suy luận, đồng thời vẫn ưu tiên tốc độ và chi phí. Gemini 2.5 Flash là mô hình suy luận kết hợp hoàn toàn đầu tiên của chúng tôi, cho phép các nhà phát triển bật hoặc tắt khả năng “tư duy”. Mô hình này cũng cho phép các nhà phát triển đặt ngân sách tư duy để tìm ra sự cân bằng phù hợp giữa chất lượng, chi phí và độ trễ. Ngay cả khi tắt tư duy, các nhà phát triển vẫn có thể duy trì tốc độ nhanh của 2.0 Flash và cải thiện hiệu suất.
Các mô hình Gemini 2.5 của chúng tôi là các mô hình tư duy, có khả năng suy luận thông qua các suy nghĩ của chúng trước khi phản hồi. Thay vì tạo ra kết quả ngay lập tức, mô hình có thể thực hiện một quy trình “tư duy” để hiểu rõ hơn về lời nhắc, chia nhỏ các tác vụ phức tạp và lên kế hoạch phản hồi. Đối với các tác vụ phức tạp đòi hỏi nhiều bước suy luận (như giải các bài toán hoặc phân tích các câu hỏi nghiên cứu), quá trình tư duy cho phép mô hình đưa ra các câu trả lời chính xác và toàn diện hơn. Trên thực tế, Gemini 2.5 Flash hoạt động mạnh mẽ trên Hard Prompts in LMArena, chỉ đứng sau 2.5 Pro.
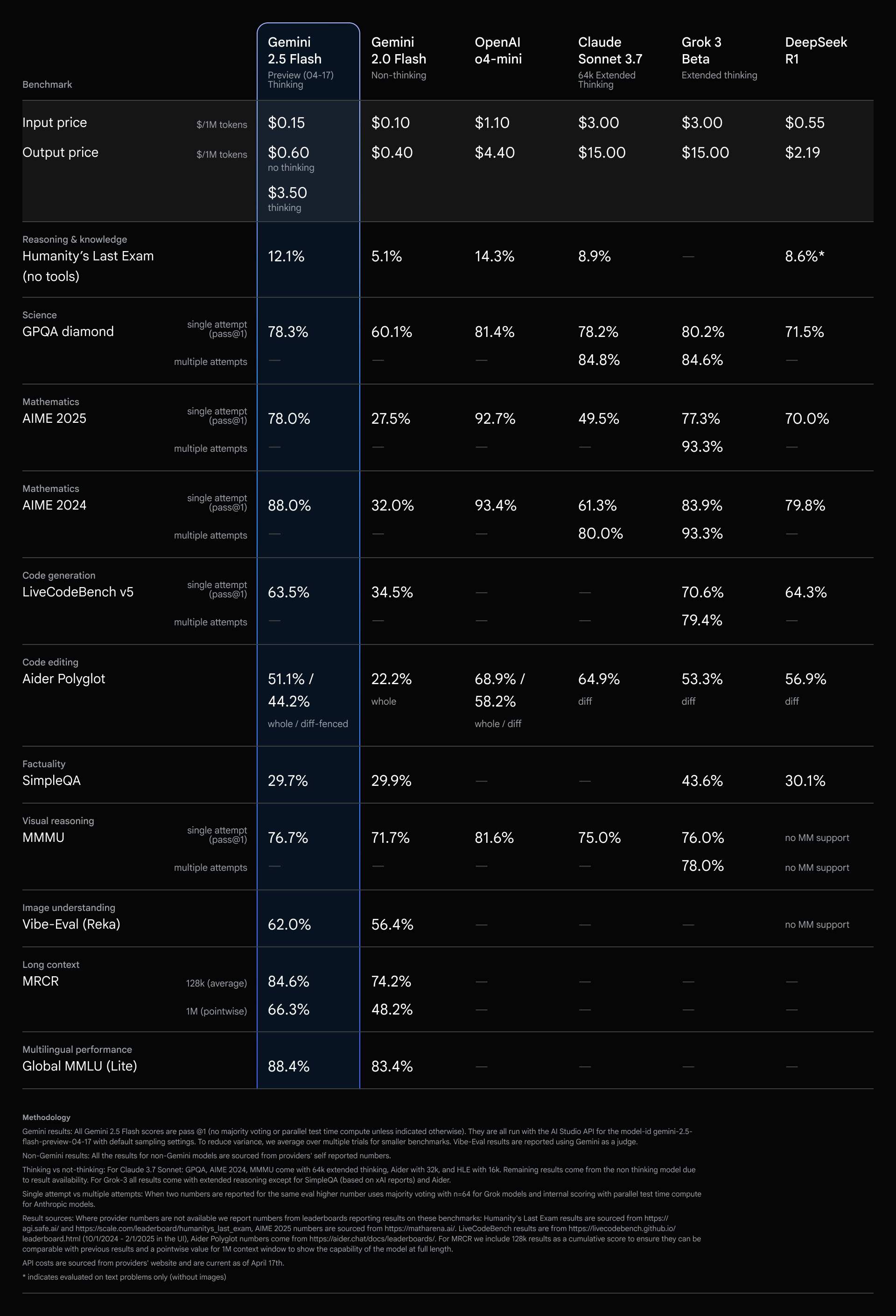
2.5 Flash có các chỉ số tương đương với các mô hình hàng đầu khác với một phần nhỏ chi phí và kích thước.
Mô hình tư duy hiệu quả chi phí nhất của chúng tôi
2.5 Flash tiếp tục dẫn đầu là mô hình có tỷ lệ giá trên hiệu suất tốt nhất.
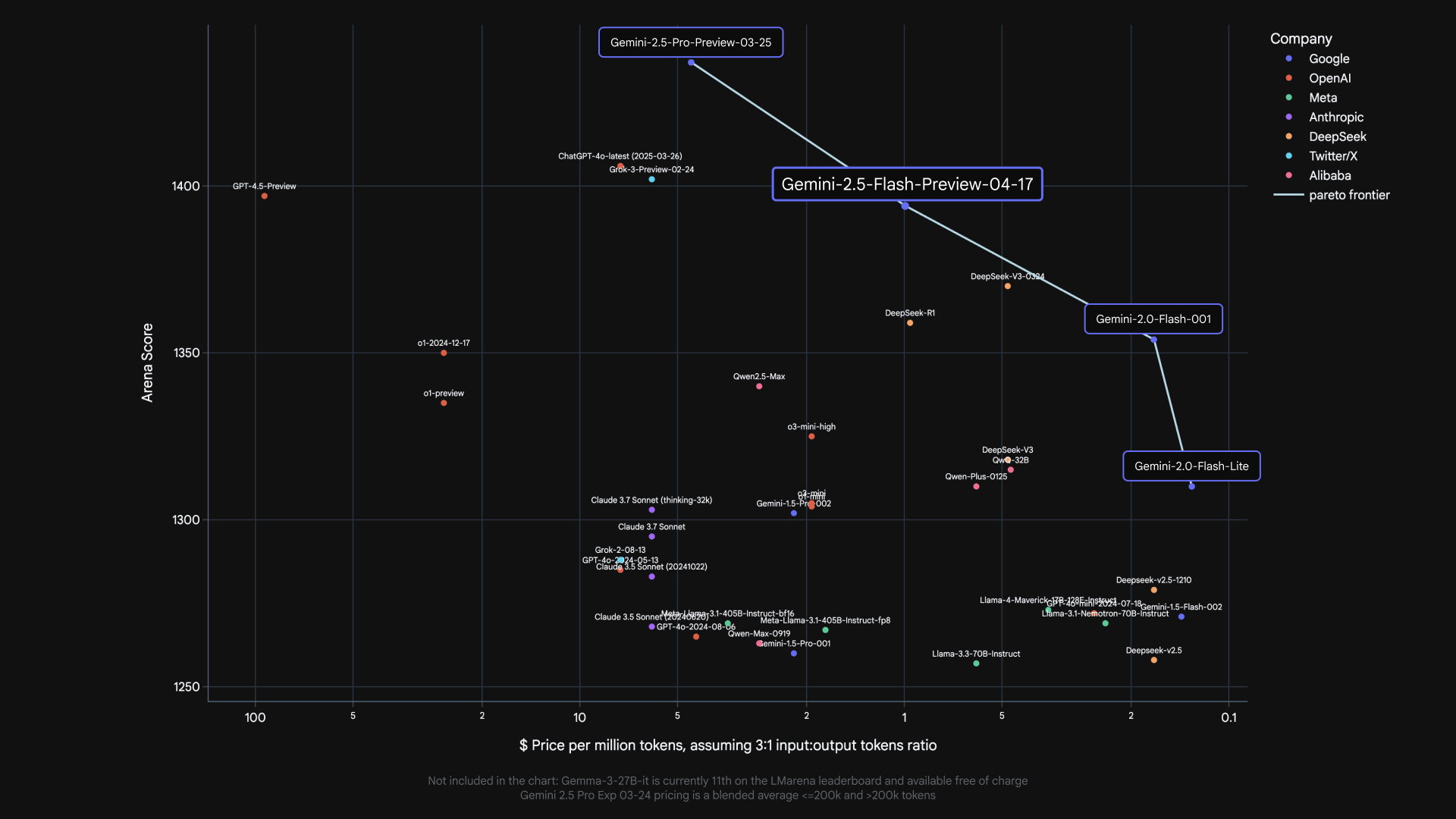
Gemini 2.5 Flash bổ sung một mô hình khác vào đường biên Pareto về chi phí so với chất lượng của Google.
Kiểm soát chi tiết để quản lý tư duy
Chúng tôi biết rằng các trường hợp sử dụng khác nhau có sự đánh đổi khác nhau về chất lượng, chi phí và độ trễ. Để mang lại sự linh hoạt cho các nhà phát triển, chúng tôi đã cho phép cài đặt ngân sách tư duy cung cấp khả năng kiểm soát chi tiết số lượng mã thông báo tối đa mà một mô hình có thể tạo ra trong khi tư duy. Ngân sách cao hơn cho phép mô hình suy luận sâu hơn để cải thiện chất lượng. Tuy nhiên, điều quan trọng là, ngân sách đặt ra giới hạn về mức độ tư duy của 2.5 Flash, nhưng mô hình không sử dụng toàn bộ ngân sách nếu lời nhắc không yêu cầu.
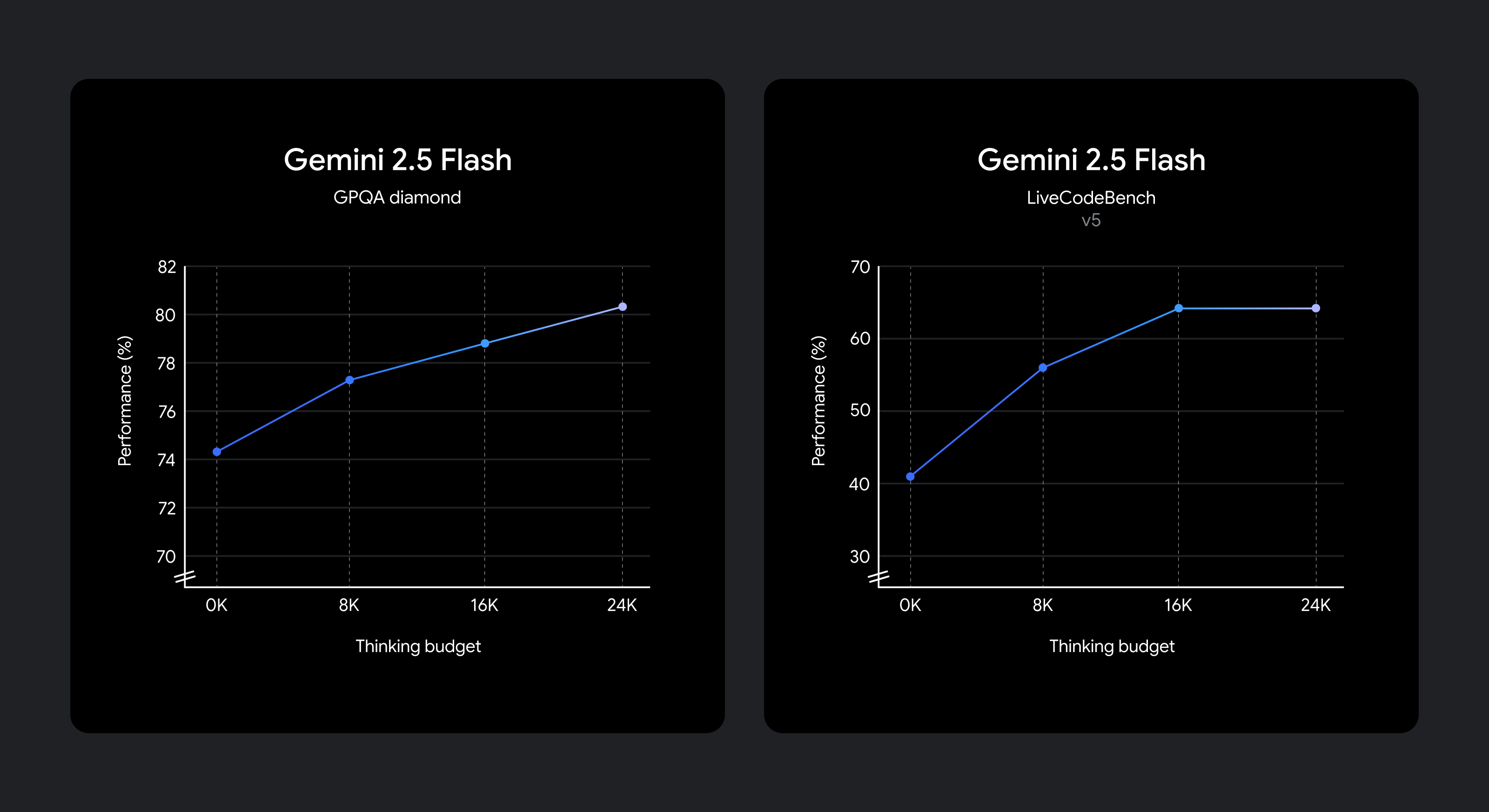
Cải thiện chất lượng suy luận khi ngân sách tư duy tăng lên.
Mô hình được đào tạo để biết thời gian tư duy cho một lời nhắc nhất định và do đó tự động quyết định mức độ tư duy dựa trên độ phức tạp của tác vụ được nhận biết.
Nếu bạn muốn giữ chi phí và độ trễ thấp nhất trong khi vẫn cải thiện hiệu suất so với 2.0 Flash, hãy đặt ngân sách tư duy thành 0. Bạn cũng có thể chọn đặt ngân sách mã thông báo cụ thể cho giai đoạn tư duy bằng cách sử dụng tham số trong API hoặc thanh trượt trong Google AI Studio và Vertex AI. Ngân sách có thể dao động từ 0 đến 24576 mã thông báo cho 2.5 Flash.
Các lời nhắc sau đây chứng minh mức độ suy luận có thể được sử dụng trong chế độ mặc định của 2.5 Flash.
Lời nhắc yêu cầu suy luận thấp:
Ví dụ 1: “Cảm ơn” trong tiếng Tây Ban Nha
Ví dụ 2: Canada có bao nhiêu tỉnh?
Lời nhắc yêu cầu suy luận trung bình:
Ví dụ 1: Bạn tung hai con xúc xắc. Xác suất để chúng cộng lại thành 7 là bao nhiêu?
Ví dụ 2: Phòng tập thể dục của tôi có giờ chơi bóng rổ giữa 9-3 giờ chiều vào các ngày Thứ Hai, Thứ Tư, Thứ Sáu và giữa 2-8 giờ chiều vào Thứ Ba và Thứ Bảy. Nếu tôi làm việc từ 9-6 giờ chiều 5 ngày một tuần và muốn chơi 5 giờ bóng rổ vào các ngày trong tuần, hãy tạo một lịch trình cho tôi để mọi thứ hoạt động.
Lời nhắc yêu cầu suy luận cao:
Ví dụ 1: Một dầm công xôn có chiều dài L=3m có mặt cắt hình chữ nhật (chiều rộng b=0.1m, chiều cao h=0.2m) và được làm bằng thép (E=200 GPa). Nó chịu một tải trọng phân bố đều w=5 kN/m dọc theo toàn bộ chiều dài và một tải trọng điểm P=10 kN ở đầu tự do của nó. Tính ứng suất uốn tối đa (σ_max).
Ví dụ 2: Viết một hàm evaluate_cells(cells: Dict[str, str]) -> Dict[str, float] tính toán các giá trị của các ô trong bảng tính.
Mỗi ô chứa:
- Một số (ví dụ:
"3") - Hoặc một công thức như
"=A1 + B1 * 2"sử dụng+,-,*,/và các ô khác.
Yêu cầu:
- Giải quyết các phụ thuộc giữa các ô.
- Xử lý thứ tự ưu tiên của toán tử (
*/trước+-). - Phát hiện chu kỳ và đưa ra
ValueError("Đã phát hiện chu kỳ tại <cell>"). - Không có
eval(). Chỉ sử dụng các thư viện tích hợp.
Bắt đầu xây dựng với Gemini 2.5 Flash ngay hôm nay
Gemini 2.5 Flash với khả năng tư duy hiện đã có ở chế độ xem trước thông qua Gemini API trong Google AI Studio và trong Vertex AI, và trong một danh sách thả xuống chuyên dụng trong ứng dụng Gemini. Chúng tôi khuyến khích bạn thử nghiệm với tham số thinking_budget và khám phá cách lý luận có thể kiểm soát có thể giúp bạn giải quyết các vấn đề phức tạp hơn.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)
Tìm tài liệu tham khảo API chi tiết và hướng dẫn tư duy trong tài liệu dành cho nhà phát triển của chúng tôi hoặc bắt đầu với các ví dụ về mã từ Sổ tay nấu ăn Gemini.
Chúng tôi sẽ tiếp tục cải thiện Gemini 2.5 Flash, với nhiều tính năng sắp ra mắt, trước khi chúng tôi cung cấp nó một cách rộng rãi để sử dụng cho mục đích sản xuất đầy đủ.
*Giá mô hình được lấy từ Tài liệu của Artificial Analysis & Company
Link bài báo gốc
- Tags:
- Ai
- 17 April 2025