Gemini 2.5- Cập nhật cho dòng mô hình tư duy của chúng tôi
Khám phá các bản cập nhật mô hình Gemini 2.5 mới nhất với hiệu suất và độ chính xác nâng cao- Gemini 2.5 Pro hiện đã ổn định, Flash hiện đã có sẵn và Flash-Lite mới đang ở chế độ xem trước.
- 5 min read

Gemini 2.5: Cập nhật cho dòng mô hình tư duy của chúng tôi
Ngày 17 tháng 6 năm 2025
Shrestha Basu Mallick, Group Product Manager
Logan Kilpatrick, Group Product Manager
Hôm nay, chúng tôi rất vui mừng chia sẻ những cập nhật trên toàn bộ dòng mô hình Gemini 2.5 của chúng tôi:
- Gemini 2.5 Pro hiện đã khả dụng rộng rãi và ổn định (không có thay đổi so với bản xem trước ngày 06-05)
- Gemini 2.5 Flash hiện đã khả dụng rộng rãi và ổn định (không có thay đổi so với bản xem trước ngày 04-17, xem cập nhật giá bên dưới)
- Gemini 2.5 Flash-Lite hiện đã có sẵn ở bản xem trước
Các mô hình Gemini 2.5 là các mô hình tư duy, có khả năng suy luận thông qua các suy nghĩ của chúng trước khi phản hồi, dẫn đến hiệu suất nâng cao và độ chính xác được cải thiện. Mỗi mô hình có quyền kiểm soát ngân sách tư duy, cho phép các nhà phát triển khả năng chọn khi nào và mô hình “suy nghĩ” bao nhiêu trước khi tạo ra phản hồi.
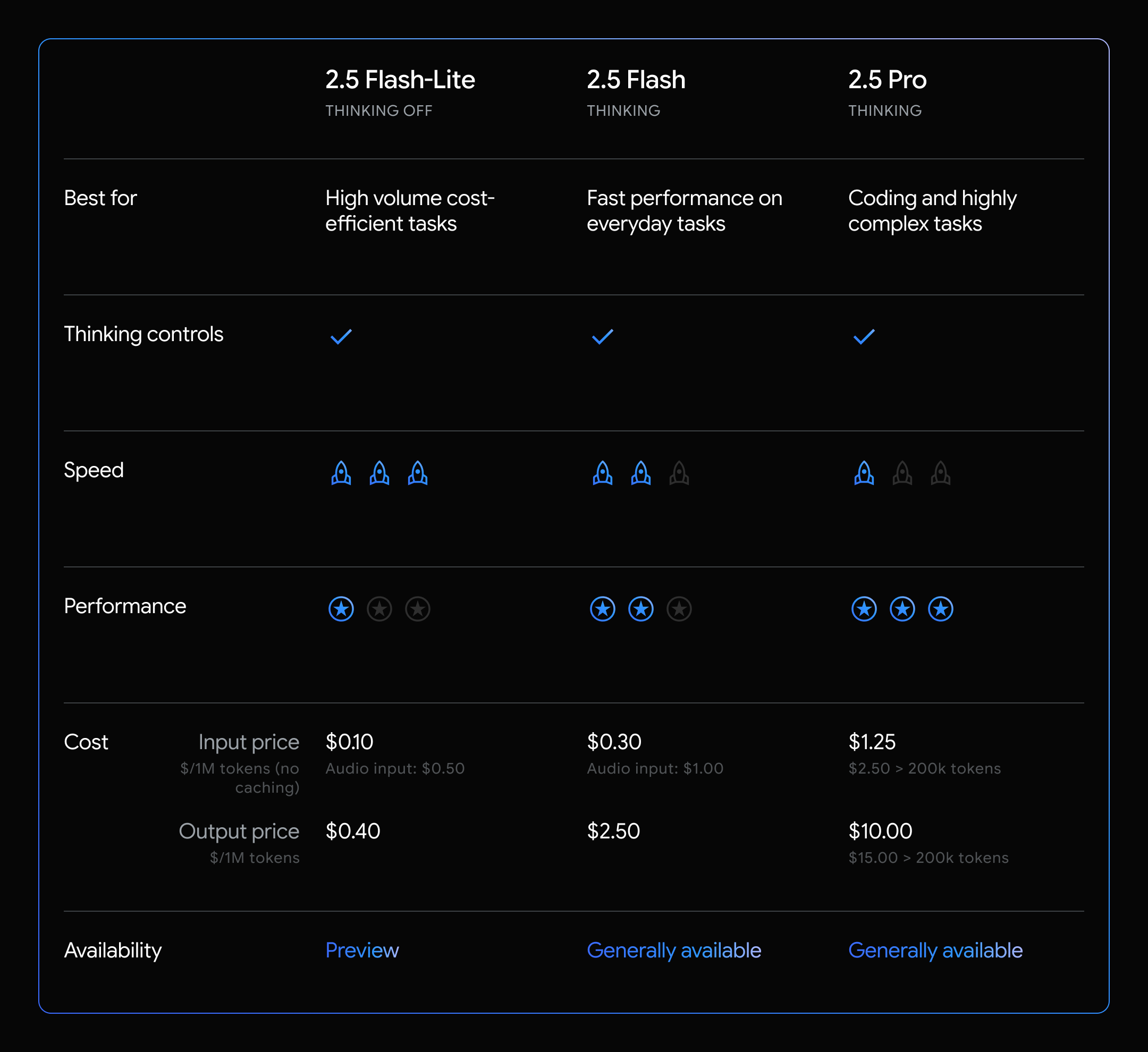
Tổng quan về dòng mô hình tư duy Gemini 2.5 của chúng tôi
Giới thiệu Gemini 2.5 Flash-Lite
Hôm nay, chúng tôi giới thiệu 2.5 Flash-Lite ở bản xem trước với độ trễ và chi phí thấp nhất trong dòng mô hình 2.5. Nó được thiết kế như một bản nâng cấp tiết kiệm chi phí từ các mô hình 1.5 và 2.0 Flash trước đây của chúng tôi. Nó cũng cung cấp hiệu suất tốt hơn trên hầu hết các đánh giá và thời gian đến mã thông báo đầu tiên thấp hơn đồng thời đạt được số lượng mã thông báo giải mã trên giây cao hơn. Mô hình này rất phù hợp cho các tác vụ thông lượng cao như phân loại hoặc tóm tắt ở quy mô lớn.
Gemini 2.5 Flash-Lite là một mô hình suy luận, cho phép kiểm soát động ngân sách tư duy bằng một tham số API. Vì Flash-Lite được tối ưu hóa cho chi phí và tốc độ, nên “tư duy” bị tắt theo mặc định, không giống như các mô hình khác của chúng tôi. 2.5 Flash-Lite cũng hỗ trợ tất cả các công cụ gốc của chúng tôi như Grounding with Google Search, Code Execution và URL Context ngoài việc gọi hàm.
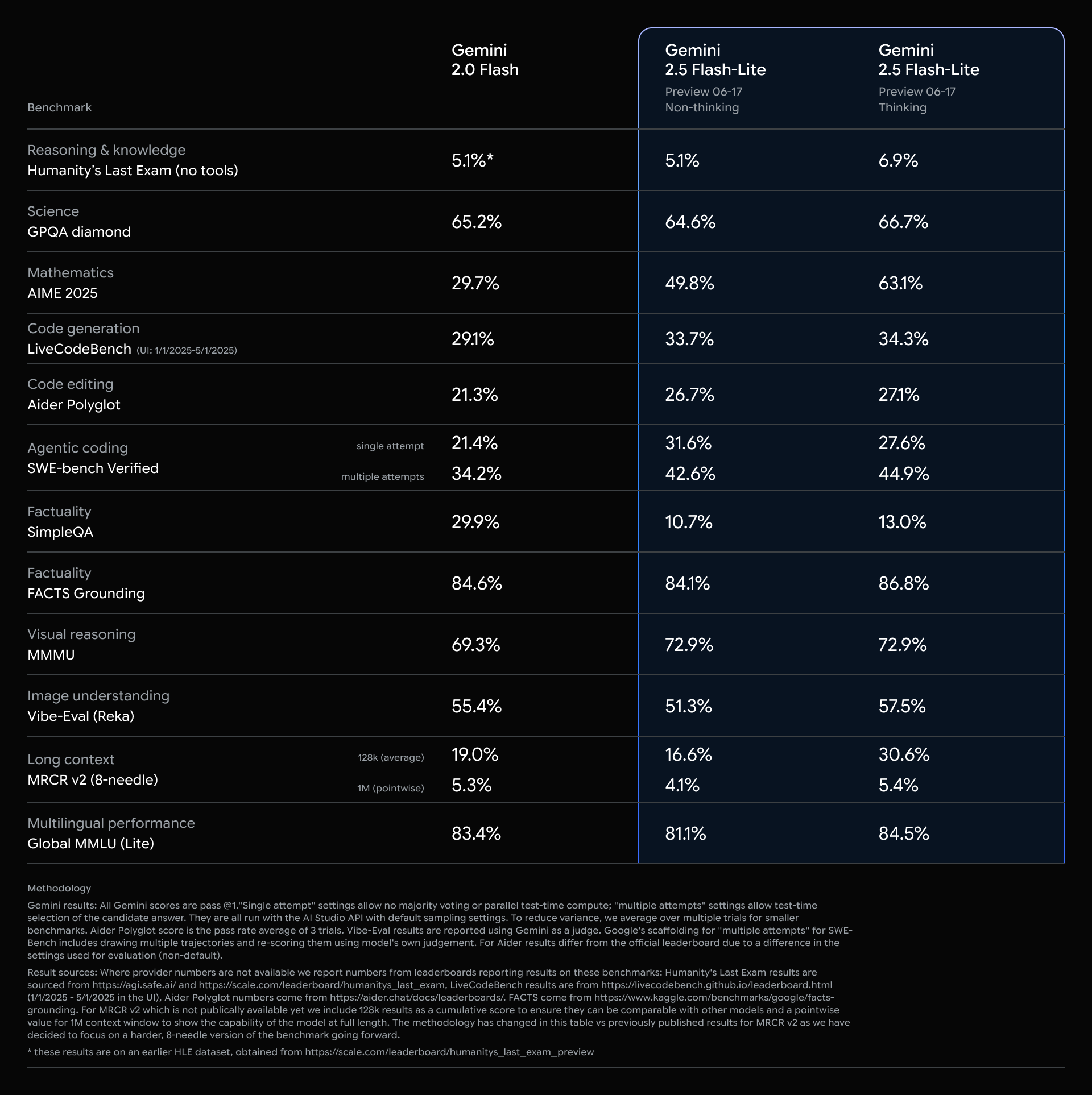
Điểm chuẩn cho Gemini 2.5 Flash-Lite
Cập nhật cho Gemini 2.5 Flash và định giá
Trong năm qua, các nhóm nghiên cứu của chúng tôi đã tiếp tục thúc đẩy biên Pareto với dòng mô hình Flash của chúng tôi. Khi 2.5 Flash được công bố ban đầu, chúng tôi vẫn chưa hoàn thiện các khả năng cho 2.5 Flash-Lite. Chúng tôi cũng ra mắt với “giá tư duy” và “giá không tư duy”, điều này gây nhầm lẫn cho các nhà phát triển.
Với phiên bản ổn định của Gemini 2.5 Flash được triển khai (giống với bản xem trước mô hình 05-20 mà chúng tôi đã cung cấp tại Google I/O) và hiệu suất đáng kinh ngạc của 2.5 Flash, chúng tôi đang cập nhật giá cho 2.5 Flash:
- $0.30 / 1M mã thông báo đầu vào (*tăng từ $0.15 đầu vào)
- $2.50 / 1M mã thông báo đầu ra (*giảm từ $3.50 đầu ra)
- Chúng tôi đã loại bỏ sự khác biệt về giá giữa tư duy và không tư duy
- Chúng tôi giữ một bậc giá duy nhất bất kể kích thước mã thông báo đầu vào
Mặc dù chúng tôi cố gắng duy trì giá nhất quán giữa bản xem trước và bản phát hành ổn định để giảm thiểu sự gián đoạn, nhưng đây là một điều chỉnh cụ thể phản ánh giá trị đặc biệt của Flash, vẫn cung cấp chi phí trên mỗi trí thông minh tốt nhất hiện có.
Và với Gemini 2.5 Flash-Lite, giờ đây chúng tôi có một tùy chọn chi phí thậm chí còn thấp hơn (có hoặc không có tư duy) cho các trường hợp sử dụng nhạy cảm về chi phí và độ trễ, đòi hỏi ít trí thông minh mô hình hơn.

Cập nhật giá cho dòng Gemini Flash của chúng tôi
Nếu bạn đang sử dụng Gemini 2.5 Flash Preview 04-17, giá xem trước hiện tại sẽ vẫn có hiệu lực cho đến khi ngừng hoạt động theo kế hoạch vào ngày 15 tháng 7 năm 2025, tại thời điểm đó, điểm cuối mô hình đó sẽ bị tắt. Bạn có thể chuyển sang mô hình khả dụng rộng rãi “gemini-2.5-flash” hoặc chuyển sang 2.5 Flash-Lite Preview như một tùy chọn chi phí thấp hơn.
Tiếp tục tăng trưởng của Gemini 2.5 Pro
Sự tăng trưởng và nhu cầu đối với Gemini 2.5 Pro tiếp tục là lớn nhất so với bất kỳ mô hình nào của chúng tôi mà chúng tôi từng thấy. Để cho phép nhiều khách hàng xây dựng trên mô hình này trong sản xuất, chúng tôi đang làm cho phiên bản 06-05 của mô hình ổn định, với cùng một mức giá biên Pareto như trước đây.
Chúng tôi hy vọng rằng các trường hợp bạn cần trí thông minh cao nhất và nhiều khả năng nhất là nơi bạn sẽ thấy Pro tỏa sáng, như mã hóa và các tác vụ đại lý. Gemini 2.5 Pro là trung tâm của nhiều công cụ dành cho nhà phát triển được yêu thích nhất.

Các công cụ dành cho nhà phát triển hàng đầu sử dụng Gemini 2.5 Pro
Nếu bạn đang sử dụng 2.5 Pro Preview 05-06, mô hình sẽ vẫn khả dụng cho đến ngày 19 tháng 6 năm 2025 và sau đó sẽ bị tắt. Nếu bạn đang sử dụng 2.5 Pro Preview 06-05, bạn chỉ cần cập nhật chuỗi mô hình của mình thành “gemini-2.5-pro”.
Chúng tôi rất nóng lòng muốn thấy nhiều lĩnh vực hơn nữa hưởng lợi từ trí thông minh của 2.5 Pro và mong muốn chia sẻ thêm về việc mở rộng quy mô vượt ra ngoài Pro trong tương lai gần.