GSPO- Hướng tới Học tăng cường có khả năng mở rộng cho Mô hình ngôn ngữ
Học tăng cường (RL) đã nổi lên như một mô hình then chốt để mở rộng mô hình ngôn ngữ và nâng cao khả năng suy luận sâu và giải quyết vấn đề của chúng.
- 7 min read
GSPO: Hướng tới Học Tăng Cường Khả Mở rộng cho Mô hình Ngôn ngữ
Giới thiệu
Học tăng cường (RL) đã nổi lên như một mô hình then chốt để mở rộng các mô hình ngôn ngữ và nâng cao khả năng giải quyết vấn đề và suy luận sâu sắc của chúng. Để mở rộng RL, điều kiện tiên quyết quan trọng nhất là duy trì động lực huấn luyện ổn định và mạnh mẽ. Tuy nhiên, chúng tôi nhận thấy rằng các thuật toán RL hiện có (như GRPO) thể hiện các vấn đề về tính không ổn định nghiêm trọng trong quá trình huấn luyện dài hạn và dẫn đến sự sụp đổ mô hình không thể đảo ngược, cản trở việc cải thiện hiệu suất hơn nữa khi tăng khả năng tính toán.
Để cho phép mở rộng RL thành công, chúng tôi đề xuất thuật toán Tối ưu hóa Chính sách Chuỗi Nhóm (GSPO). Không giống như các thuật toán RL trước đây, GSPO xác định tỷ lệ quan trọng dựa trên khả năng xảy ra của chuỗi và thực hiện cắt tỉa, khen thưởng và tối ưu hóa ở cấp chuỗi. So với GRPO, GSPO thể hiện những ưu điểm vượt trội ở các khía cạnh sau:
- Hiệu quả và Năng suất: GSPO có hiệu quả huấn luyện cao hơn đáng kể và có thể đạt được những cải tiến hiệu suất liên tục thông qua việc tăng khả năng tính toán huấn luyện;
- Đặc biệt Ổn định: GSPO duy trì các quy trình huấn luyện ổn định và giải quyết một cách vốn có những thách thức về độ ổn định trong quá trình huấn luyện RL của các mô hình Mixture-of-Experts (MoE) lớn;
- Thân thiện với Cơ sở hạ tầng: Do tối ưu hóa ở cấp chuỗi, GSPO về cơ bản có khả năng chịu đựng sự khác biệt về độ chính xác cao hơn, mang lại tiềm năng hấp dẫn để đơn giản hóa cơ sở hạ tầng RL.
Những ưu điểm này đã góp phần vào hiệu suất vượt trội của các mô hình Qwen3 mới nhất (Instruct, Coder, Thinking).
Mục tiêu Tối ưu hóa Cấp Chuỗi
Giả sử $x$ là một truy vấn, $\pi_{\theta_\mathrm{old}}$ là chính sách cũ tạo ra các phản hồi, ${y_i}{i=1}^G$ là nhóm phản hồi được lấy mẫu, $\widehat{A}{i}$ là lợi thế tương đối của nhóm đối với mỗi phản hồi và $\pi_\theta$ là chính sách hiện tại sẽ được tối ưu hóa. GSPO áp dụng mục tiêu tối ưu hóa sau:
$$ \mathcal{J}\text{GSPO} (\theta) =, \mathbb{E}{ x \sim \mathcal{D},, {y_i}{i=1}^G \sim \pi{\theta_\mathrm{old}}( \cdot | x) } \left[ \frac{1}{G} \sum_{i=1}^{G} \min \left( s_{i}(\theta) \widehat{A}{i}, , \mathrm{clip} \left( s{i}(\theta), 1 - {\varepsilon}, 1 + {\varepsilon} \right) \widehat{A}_{i} \right) \right], $$
trong đó
$$ s_{i}(\theta)
\left( \frac{ \pi_{\theta} (y_i | x) }{ \pi_{\theta_\text{old}} (y_i | x)} \right)^{\frac{1}{|y_i|}}
\exp \left( \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \log \frac{ \pi_{\theta} (y_{i,t} | x, y_{i,<t}) }{ \pi_{\theta_\text{old}} (y_{i,t} | x,y_{i,<t})} \right). $$
Ở đây, $s_i(\theta)$ là tỷ lệ quan trọng được xác định dựa trên khả năng xảy ra của chuỗi trong GSPO, trong đó chúng ta thực hiện chuẩn hóa độ dài để giảm phương sai và thống nhất phạm vi số của $s_i(\theta)$.
Hiệu quả và Hiệu suất Huấn luyện
Chúng tôi thử nghiệm với một mô hình khởi động nguội được tinh chỉnh từ Qwen3-30B-A3B-Base và báo cáo các đường cong phần thưởng huấn luyện cũng như các đường cong hiệu suất trên các điểm chuẩn AIME'24, LiveCodeBench và CodeForces. Chúng tôi so sánh với GRPO làm đường cơ sở. Lưu ý rằng GRPO đòi hỏi chiến lược huấn luyện Routing Replay để hội tụ bình thường của MoE RL (mà chúng ta sẽ thảo luận sau), trong khi GSPO đã loại bỏ sự cần thiết của chiến lược này.

Như trong hình trên, GSPO thể hiện hiệu quả huấn luyện cao hơn đáng kể so với GRPO, đạt được hiệu suất tốt hơn với cùng chi phí huấn luyện. Đặc biệt, chúng tôi nhận thấy rằng GSPO có thể mang lại sự cải thiện hiệu suất liên tục thông qua việc tăng khả năng tính toán huấn luyện, thường xuyên cập nhật bộ truy vấn và kéo dài độ dài thế hệ — đây chính xác là khả năng mở rộng mà chúng tôi mong đợi từ một thuật toán. Cuối cùng, chúng tôi đã áp dụng thành công GSPO vào quá trình huấn luyện RL quy mô lớn của các mô hình Qwen3 mới nhất, tiếp tục giải phóng tiềm năng mở rộng RL!
Một quan sát thú vị là tỷ lệ mã thông báo được cắt trong GSPO cao hơn hai bậc so với trong GRPO (như trong hình bên dưới), trong khi GSPO vẫn đạt được hiệu quả huấn luyện cao hơn. Điều này tiếp tục chứng minh rằng mục tiêu tối ưu hóa ở cấp mã thông báo của GRPO ồn ào và không hiệu quả, trong khi phương pháp tiếp cận ở cấp chuỗi của GSPO cung cấp tín hiệu học tập đáng tin cậy và hiệu quả hơn.
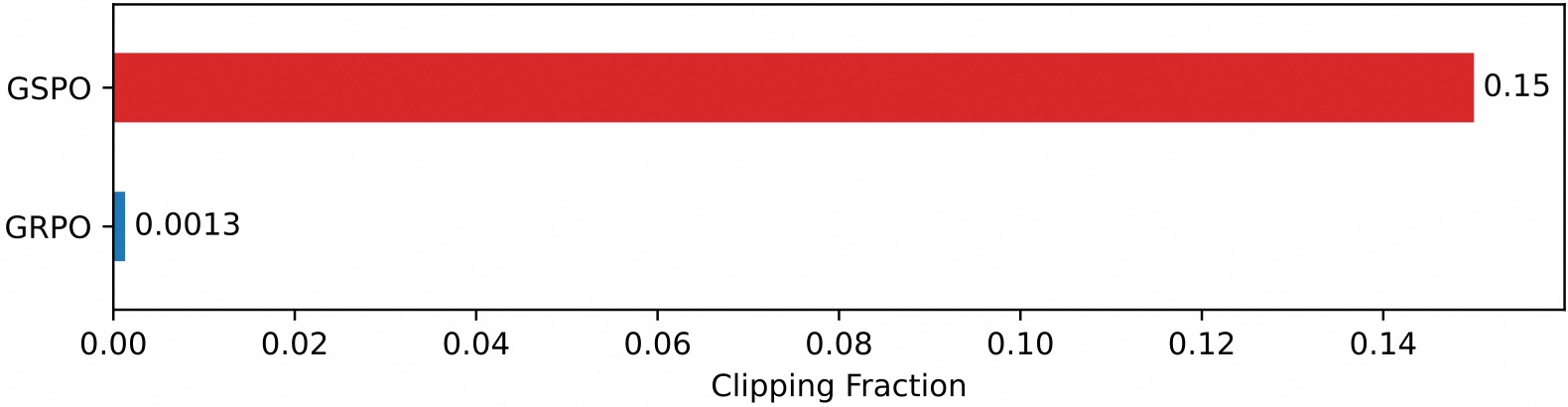
Lợi ích cho MoE RL và Cơ sở hạ tầng
Chúng tôi phát hiện ra rằng khi áp dụng thuật toán GRPO, tính biến động kích hoạt chuyên gia của các mô hình MoE ngăn cản quá trình huấn luyện RL hội tụ đúng cách. Để giải quyết thách thức này, trước đây chúng tôi đã sử dụng chiến lược huấn luyện Routing Replay, trong đó lưu trữ các chuyên gia được kích hoạt trong $\pi_{\theta_\text{old}}$ và “phát lại” các mẫu định tuyến này trong $\pi_\theta$ khi tính toán tỷ lệ quan trọng. Như trong hình bên dưới, Routing Replay rất quan trọng để hội tụ bình thường của quá trình huấn luyện GRPO trên các mô hình MoE. Tuy nhiên, chiến lược Routing Replay phát sinh thêm chi phí bộ nhớ và giao tiếp và có thể giới hạn dung lượng thực tế của các mô hình MoE.
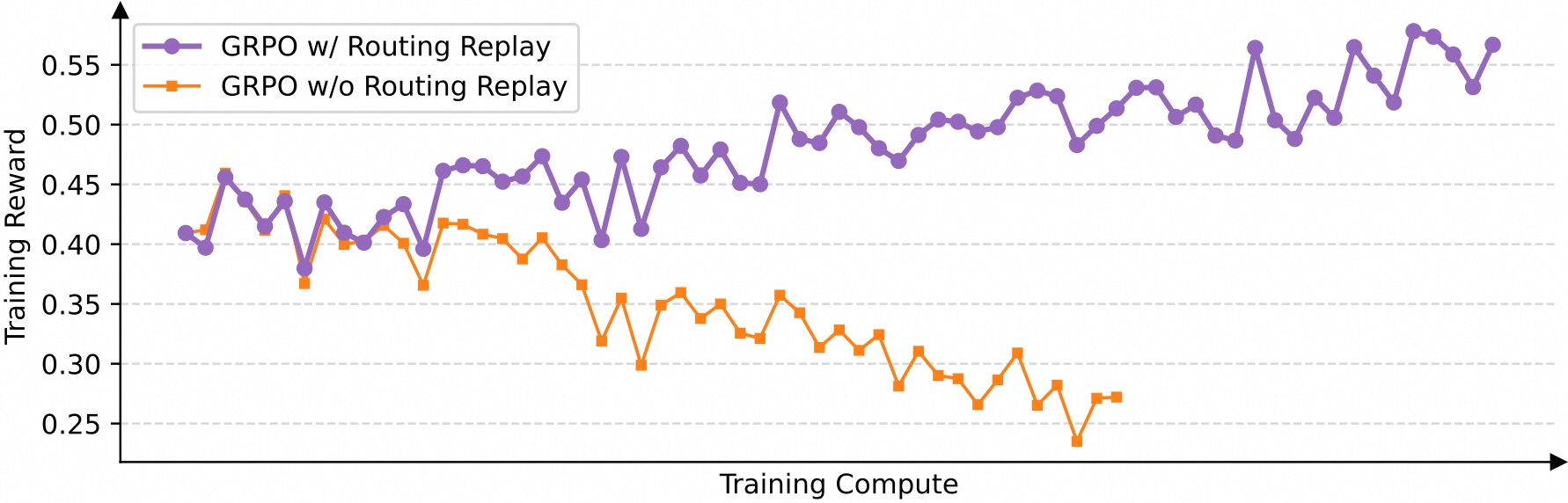
Ưu điểm đáng chú ý của GSPO nằm ở việc loại bỏ hoàn toàn sự phụ thuộc vào Routing Replay. Điểm mấu chốt là GSPO chỉ tập trung vào khả năng xảy ra ở cấp chuỗi (tức là, $\pi_\theta(y_i|x)$) và không nhạy cảm với khả năng xảy ra của mã thông báo riêng lẻ (tức là, $\pi_\theta(y_{i,t}|x,y_{i,<t})$). Do đó, nó không yêu cầu các giải pháp thay thế nặng về cơ sở hạ tầng như Routing Replay, cả đơn giản hóa và ổn định quy trình huấn luyện đồng thời cho phép các mô hình tối đa hóa dung lượng của chúng.
Ngoài ra, vì GSPO chỉ sử dụng khả năng xảy ra ở cấp chuỗi thay vì cấp mã thông báo để tối ưu hóa, nên một cách trực quan, cái trước có khả năng chịu đựng sự khác biệt về độ chính xác cao hơn nhiều. Do đó, GSPO giúp có thể sử dụng trực tiếp khả năng xảy ra được trả về bởi các công cụ suy luận để tối ưu hóa, loại bỏ nhu cầu tính toán lại bằng các công cụ huấn luyện. Điều này đặc biệt có lợi trong các tình huống như triển khai một phần, RL nhiều lượt và khung hình tách rời huấn luyện-suy luận.
Kết luận
Chúng tôi đề xuất Tối ưu hóa Chính sách Chuỗi Nhóm (GSPO), một thuật toán RL mới để huấn luyện các mô hình ngôn ngữ. GSPO thể hiện tính ổn định, hiệu quả và hiệu suất huấn luyện vượt trội so với GRPO và thể hiện hiệu quả đặc biệt đối với quá trình huấn luyện RL quy mô lớn của các mô hình MoE, đặt nền móng cho những cải tiến vượt trội trong các mô hình Qwen3 mới nhất. Với GSPO là nền tảng thuật toán của chúng tôi, chúng tôi sẽ tiếp tục vượt qua các ranh giới của việc mở rộng RL và mong muốn những tiến bộ cơ bản về trí thông minh.
Trích dẫn
Nếu bạn thấy công trình của chúng tôi hữu ích, vui lòng trích dẫn chúng tôi.
@article{gspo,
title={Group Sequence Policy Optimization},
author={
Chujie Zheng and Shixuan Liu and Mingze Li and Xiong-Hui Chen and Bowen Yu and
Chang Gao and Kai Dang and Yuqiong Liu and Rui Men and An Yang and Jingren Zhou and
Junyang Lin
},
journal={arXiv preprint arXiv:2507.18071},
year={2025}
}
### [Link bài viết gốc](https://qwenlm.github.io/blog/gspo/)
- Tags:
- Ai
- July 27, 2025
- Qwenlm.github.io