Giới thiệu Claude Haiku 4.5
Giới thiệu Claude Haiku 4.5, một bản cập nhật cho mô hình hiệu suất cao của chúng tôi, mang đến những cải tiến về tốc độ và khả năng.
- 9 min read

Giới thiệu Claude Haiku 4.5 - Mô hình nhỏ mới nhất của Anthropic, đã có sẵn cho mọi người dùng.
Claude Haiku 4.5, mô hình nhỏ mới nhất của chúng tôi, đã có mặt ngay hôm nay cho tất cả người dùng.
Những gì trước đây là công nghệ tiên tiến giờ đây đã rẻ hơn và nhanh hơn. Năm tháng trước, Claude Sonnet 4 là một mô hình tiên tiến. Ngày nay, Claude Haiku 4.5 mang lại cho bạn hiệu suất lập trình tương tự nhưng với chi phí chỉ bằng một phần ba và tốc độ nhanh hơn gấp đôi.
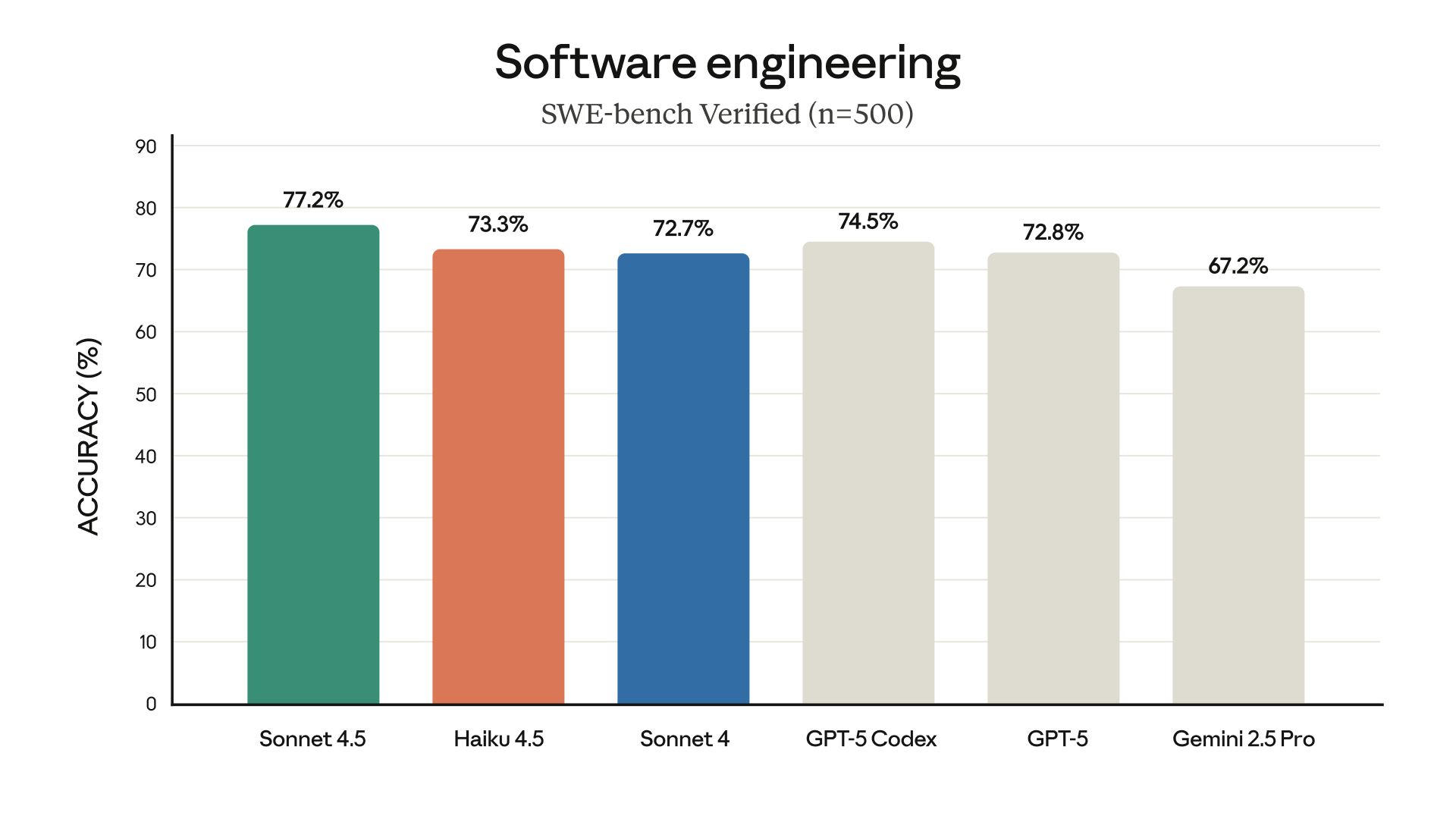
Claude Haiku 4.5 thậm chí còn vượt trội hơn Claude Sonnet 4 trong một số tác vụ, ví dụ như sử dụng máy tính. Những tiến bộ này giúp các ứng dụng như Claude for Chrome nhanh hơn và hữu ích hơn bao giờ hết.
Những người dùng dựa vào AI cho các tác vụ thời gian thực, độ trễ thấp như trợ lý trò chuyện, đại diện dịch vụ khách hàng hoặc lập trình cặp đôi sẽ đánh giá cao sự kết hợp giữa trí tuệ cao và tốc độ đáng kinh ngạc của Haiku 4.5. Và người dùng Claude Code sẽ thấy rằng Haiku 4.5 giúp trải nghiệm lập trình — từ các dự án đa tác tử đến tạo mẫu nhanh — phản hồi nhanh hơn đáng kể.
Claude Sonnet 4.5, được phát hành hai tuần trước, vẫn là mô hình tiên tiến của chúng tôi và là mô hình lập trình tốt nhất trên thế giới. Claude Haiku 4.5 mang đến cho người dùng một lựa chọn mới khi họ muốn hiệu suất gần với tiên tiến nhất nhưng hiệu quả chi phí cao hơn nhiều. Nó cũng mở ra những cách mới để sử dụng các mô hình của chúng tôi cùng nhau. Ví dụ, Sonnet 4.5 có thể chia nhỏ một vấn đề phức tạp thành các kế hoạch nhiều bước, sau đó điều phối một nhóm các Haiku 4.5 để hoàn thành các nhiệm vụ phụ song song.
Claude Haiku 4.5 có mặt ở mọi nơi ngay hôm nay. Nếu bạn là nhà phát triển, chỉ cần sử dụng claude-haiku-4-5 thông qua Claude API. Giá hiện là $1/$5 cho mỗi triệu token đầu vào và đầu ra.
Điểm chuẩn
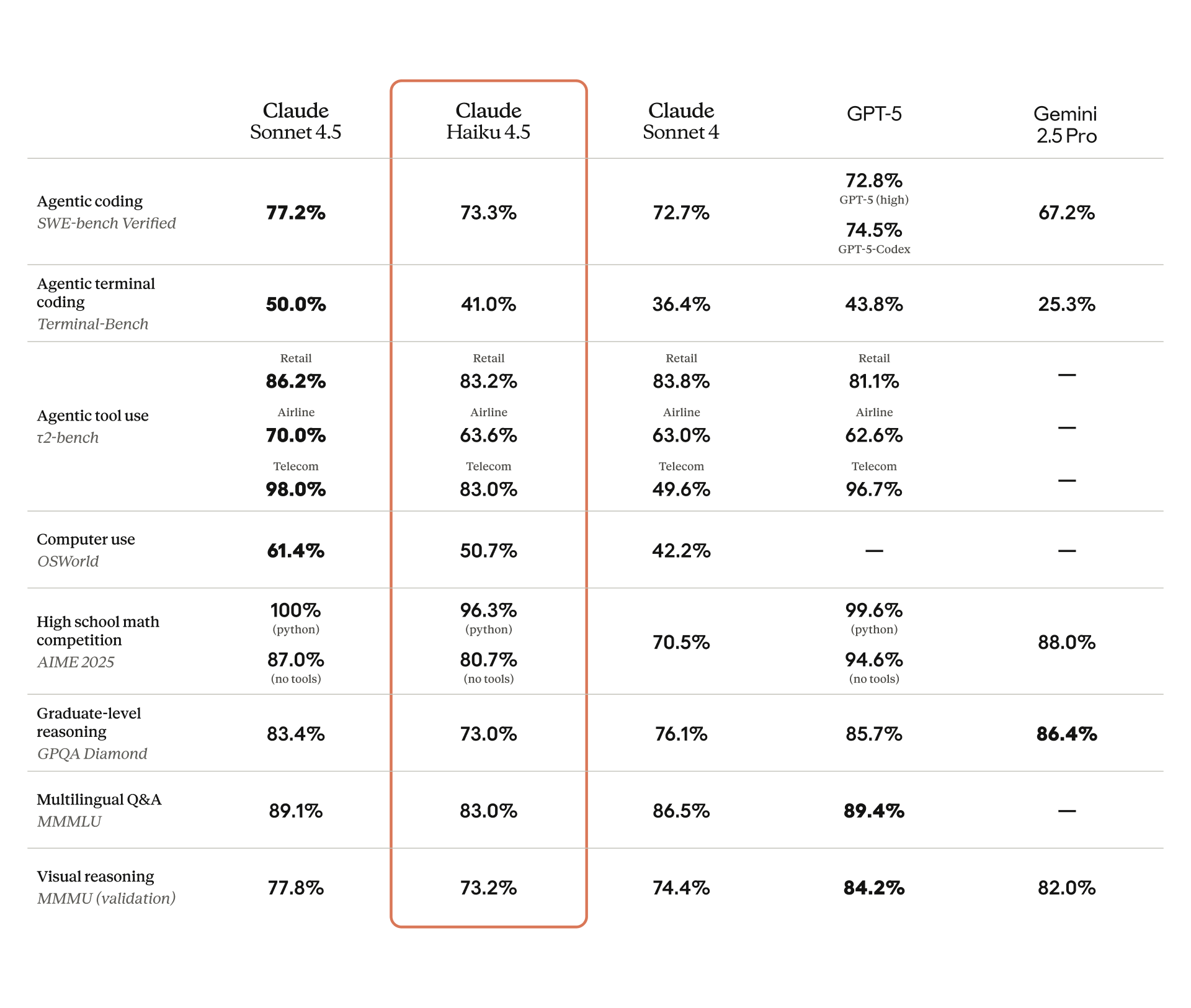
“Claude Haiku 4.5 đạt được điểm ngọt mà chúng tôi không nghĩ là có thể: chất lượng lập trình gần như tiên tiến với tốc độ và hiệu quả chi phí cực nhanh. Trong đánh giá lập trình tác tử của Augment, nó đạt 90% hiệu suất của Sonnet 4.5, sánh ngang với các mô hình lớn hơn nhiều. Chúng tôi rất vui mừng được cung cấp nó cho người dùng của mình.”
Guy Gur-Ari Đồng sáng lập
“Claude Haiku 4.5 là một bước nhảy vọt cho lập trình tác tử, đặc biệt đối với các tác vụ điều phối tác tử phụ và sử dụng máy tính. Khả năng phản hồi làm cho phát triển được hỗ trợ bởi AI trong Warp có cảm giác tức thời.”
Zach Lloyd Người sáng lập & CEO
“Trong lịch sử, các mô hình đã hy sinh tốc độ và chi phí để đổi lấy chất lượng. Claude Haiku 4.5 đang làm mờ ranh giới của sự đánh đổi này: nó là một mô hình tiên tiến nhanh chóng, giữ chi phí hiệu quả và báo hiệu về hướng đi của loại mô hình này.”
Jeff Wang CEO
“Claude Haiku 4.5 mang lại trí thông minh mà không phải hy sinh tốc độ, cho phép chúng tôi xây dựng các ứng dụng AI tận dụng cả suy luận sâu và khả năng phản hồi theo thời gian thực.”
Ben Lafferty Kỹ sư chính
“Claude Haiku 4.5 rất có năng lực—chỉ sáu tháng trước, mức hiệu suất này sẽ là tiên tiến nhất trên các điểm chuẩn nội bộ của chúng tôi. Bây giờ, nó chạy nhanh hơn tới 4-5 lần so với Sonnet 4.5 với chi phí chỉ bằng một phần nhỏ, mở ra một bộ trường hợp sử dụng hoàn toàn mới.”
Andrew Filev CEO
“Tốc độ là biên giới mới cho các tác tử AI hoạt động trong vòng lặp phản hồi. Haiku 4.5 chứng minh rằng bạn có thể có cả trí thông minh và đầu ra nhanh chóng. Nó xử lý các quy trình làm việc phức tạp một cách đáng tin cậy, tự sửa lỗi theo thời gian thực và duy trì động lực mà không có chi phí trễ. Đối với hầu hết các tác vụ phát triển, đó là sự cân bằng hiệu suất lý tưởng.”
Brad Axen Trưởng nhóm Kỹ thuật AI
“Claude Haiku 4.5 vượt trội hơn các mô hình hiện tại của chúng tôi trong việc tuân theo chỉ dẫn để tạo văn bản slide, đạt độ chính xác 65% so với 44% từ mô hình cao cấp của chúng tôi—đó là một yếu tố thay đổi cuộc chơi đối với chi phí hoạt động của chúng tôi.”
Jon Noronha Đồng sáng lập, Gamma
“Các thử nghiệm ban đầu của chúng tôi cho thấy Claude Haiku 4.5 mang lại khả năng tạo mã hiệu quả cho GitHub Copilot với chất lượng tương đương Sonnet 4 nhưng tốc độ nhanh hơn. Chúng tôi đã thấy nó là một lựa chọn tuyệt vời cho người dùng Copilot coi trọng tốc độ và khả năng phản hồi trong quy trình làm việc phát triển được hỗ trợ bởi AI của họ.”
Matthew Isabel Quản lý Sản phẩm Xuất sắc
Đánh giá an toàn
Chúng tôi đã thực hiện một loạt đánh giá chi tiết về an toàn và liên kết trên Claude Haiku 4.5. Mô hình cho thấy tỷ lệ hành vi đáng lo ngại thấp, và liên kết tốt hơn đáng kể so với phiên bản tiền nhiệm, Claude Haiku 3.5. Trong đánh giá liên kết tự động của chúng tôi, Claude Haiku 4.5 cũng cho thấy tỷ lệ hành vi không liên kết thấp hơn đáng kể về mặt thống kê so với cả Claude Sonnet 4.5 và Claude Opus 4.1—biến Claude Haiku 4.5, theo chỉ số này, trở thành mô hình an toàn nhất của chúng tôi cho đến nay.
Các thử nghiệm an toàn của chúng tôi cũng cho thấy Claude Haiku 4.5 chỉ gây ra rủi ro hạn chế về việc sản xuất vũ khí hóa học, sinh học, phóng xạ và hạt nhân (CBRN). Vì lý do đó, chúng tôi đã phát hành nó theo tiêu chuẩn An toàn AI Cấp 2 (ASL-2) — so với ASL-3 nghiêm ngặt hơn đối với Sonnet 4.5 và Opus 4.1. Bạn có thể đọc đầy đủ lý do đằng sau phân loại ASL-2 của mô hình, cũng như chi tiết về tất cả các bài kiểm tra an toàn khác của chúng tôi, trong thẻ hệ thống Claude Haiku 4.5.
Thông tin thêm
Claude Haiku 4.5 hiện có sẵn trên Claude Code và các ứng dụng của chúng tôi. Hiệu quả của nó có nghĩa là bạn có thể đạt được nhiều hơn trong giới hạn sử dụng của mình trong khi vẫn duy trì hiệu suất mô hình cao cấp.
Các nhà phát triển có thể sử dụng Claude Haiku 4.5 trên API của chúng tôi, Amazon Bedrock và Vertex AI của Google Cloud, nơi nó đóng vai trò là giải pháp thay thế trực tiếp cho cả Haiku 3.5 và Sonnet 4 với mức giá tiết kiệm nhất của chúng tôi.
Để biết chi tiết kỹ thuật đầy đủ và kết quả đánh giá, hãy xem thẻ hệ thống, trang mô hình và tài liệu của chúng tôi.
Phương pháp luận
- SWE-bench Verified: Tất cả các kết quả của Claude đều được báo cáo bằng cách sử dụng một khung đơn giản với hai công cụ — bash và chỉnh sửa tệp bằng cách thay thế chuỗi. Chúng tôi báo cáo 73,3%, đây là điểm trung bình qua 50 lần thử, không có tính toán thời gian thử nghiệm, ngân sách suy nghĩ 128K và các tham số lấy mẫu mặc định (nhiệt độ, top_p) trên bộ dữ liệu SWE-bench Verified gồm 500 vấn đề đầy đủ.
- Điểm số được báo cáo sử dụng một bổ sung nhắc nhỏ: “Bạn nên sử dụng công cụ càng nhiều càng tốt, lý tưởng là hơn 100 lần. Bạn cũng nên tự triển khai các bài kiểm tra của mình trước khi cố gắng giải quyết vấn đề.”
- Terminal-Bench: Tất cả điểm số được báo cáo sử dụng khung tác tử mặc định (Terminus 2), với trình phân tích cú pháp XML, trung bình 11 lần chạy (6 lần không suy nghĩ (điểm 40,21%), 5 lần với ngân sách suy nghĩ 32K (điểm 41,75%)) với n-lần thử = 1.
- τ2-bench: Điểm số đạt được bằng cách lấy trung bình qua 10 lần chạy sử dụng suy nghĩ mở rộng (ngân sách suy nghĩ 128k) và các tham số lấy mẫu mặc định (nhiệt độ, top_p) với việc sử dụng công cụ và bổ sung nhắc cho Chính sách Tác tử Hàng không và Viễn thông yêu cầu Claude nhắm mục tiêu tốt hơn các trường hợp lỗi đã biết của nó khi sử dụng nhắc gốc. Một bổ sung nhắc cũng được thêm vào nhắc Người dùng Viễn thông để tránh các trường hợp lỗi từ người dùng kết thúc tương tác không chính xác.
- AIME: Điểm Haiku 4.5 được báo cáo là điểm trung bình qua 10 lần chạy độc lập, mỗi lần tính toán pass@1 trên 16 lần thử với các tham số lấy mẫu mặc định (nhiệt độ, top_p) và ngân sách suy nghĩ 128K.
- OSWorld: Tất cả điểm số được báo cáo sử dụng khung OSWorld-Verified chính thức với 100 bước tối đa, trung bình qua 4 lần chạy với tổng ngân sách suy nghĩ 128K và ngân sách suy nghĩ 2K mỗi bước được cấu hình.
- MMMLU: Tất cả điểm số được báo cáo là điểm trung bình của 10 lần chạy trên 14 ngôn ngữ không phải tiếng Anh với ngân sách suy nghĩ 128K.
- Tất cả các điểm số khác được lấy trung bình qua 10 lần chạy với các tham số lấy mẫu mặc định (nhiệt độ, top_p) và ngân sách suy nghĩ 128K.
Tất cả điểm số của OpenAI được báo cáo từ bài đăng GPT-5 của họ, bài đăng GPT-5 dành cho nhà phát triển, thẻ hệ thống GPT-5 (SWE-bench Verified được báo cáo sử dụng n=500) và bảng xếp hạng Terminal Bench (sử dụng Terminus 2). Tất cả điểm số Gemini được báo cáo từ trang web mô hình của họ, và bảng xếp hạng Terminal Bench (sử dụng Terminus 1).
Link bài viết gốc
- Tags:
- Ai
- Oct 15, 2025
- Www.anthropic.com