T5Gemma- Một bộ sưu tập mới các mô hình Gemma mã hóa-giải mã
Mô hình
- 7 min read

T5Gemma: Một bộ sưu tập mới các mô hình Gemma mã hóa-giải mã
Trong bối cảnh các mô hình ngôn ngữ lớn (LLM) đang phát triển nhanh chóng, tâm điểm chú ý chủ yếu đổ dồn vào kiến trúc chỉ có bộ giải mã (decoder-only). Mặc dù các mô hình này thể hiện khả năng ấn tượng trong nhiều tác vụ sinh văn bản, kiến trúc mã hóa-giải mã (encoder-decoder) cổ điển, như T5 (The Text-to-Text Transfer Transformer), vẫn là lựa chọn phổ biến cho nhiều ứng dụng thực tế. Các mô hình encoder-decoder thường vượt trội trong các tác vụ tóm tắt, dịch thuật, hỏi đáp, v.v., nhờ hiệu quả suy luận cao, tính linh hoạt trong thiết kế và biểu diễn bộ mã hóa phong phú để hiểu đầu vào. Tuy nhiên, kiến trúc encoder-decoder mạnh mẽ này đã nhận được ít sự chú ý tương đối.
Hôm nay, chúng tôi xem xét lại kiến trúc này và giới thiệu T5Gemma, một bộ sưu tập mới các LLM encoder-decoder được phát triển bằng cách chuyển đổi các mô hình chỉ có bộ giải mã đã được huấn luyện trước sang kiến trúc encoder-decoder thông qua kỹ thuật gọi là “thích ứng” (adaptation). T5Gemma dựa trên framework Gemma 2, bao gồm các mô hình Gemma 2 2B và 9B đã được thích ứng, cũng như một loạt các mô hình cỡ T5 mới được huấn luyện (Small, Base, Large và XL). Chúng tôi vui mừng phát hành các mô hình T5Gemma đã được huấn luyện trước và tinh chỉnh theo hướng dẫn cho cộng đồng để mở ra những cơ hội mới cho nghiên cứu và phát triển.

Từ kiến trúc chỉ có bộ giải mã sang kiến trúc mã hóa-giải mã
Trong T5Gemma, chúng tôi đặt câu hỏi: liệu chúng ta có thể xây dựng các mô hình encoder-decoder hàng đầu dựa trên các mô hình chỉ có bộ giải mã đã được huấn luyện trước hay không? Chúng tôi trả lời câu hỏi này bằng cách khám phá kỹ thuật “thích ứng mô hình” (model adaptation). Ý tưởng cốt lõi là khởi tạo các tham số của một mô hình encoder-decoder bằng cách sử dụng trọng số của một mô hình chỉ có bộ giải mã đã được huấn luyện trước, sau đó tiếp tục tinh chỉnh chúng thông qua tiền huấn luyện dựa trên UL2 hoặc PrefixLM.
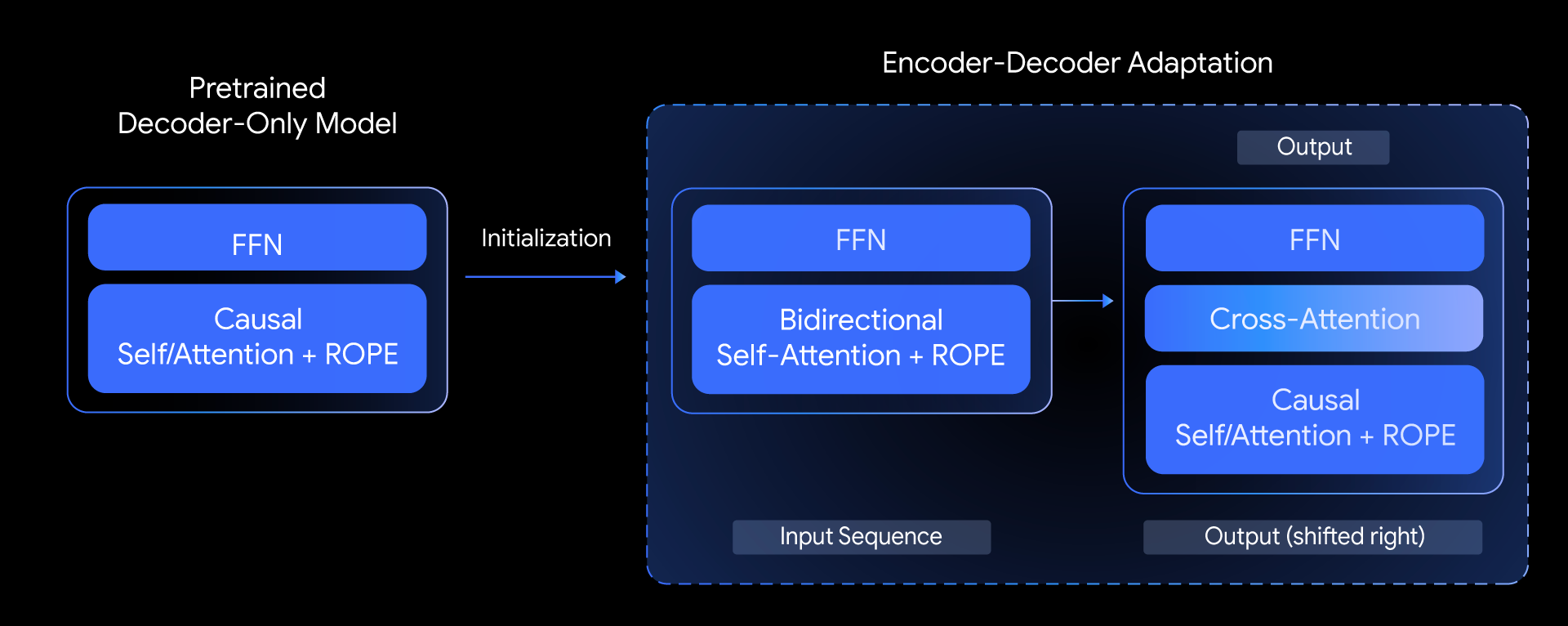 Tổng quan về phương pháp của chúng tôi, cho thấy cách chúng tôi khởi tạo một mô hình encoder-decoder mới bằng cách sử dụng các tham số từ một mô hình chỉ có bộ giải mã đã được huấn luyện trước.
Tổng quan về phương pháp của chúng tôi, cho thấy cách chúng tôi khởi tạo một mô hình encoder-decoder mới bằng cách sử dụng các tham số từ một mô hình chỉ có bộ giải mã đã được huấn luyện trước.
Phương pháp thích ứng này rất linh hoạt, cho phép kết hợp sáng tạo các kích thước mô hình khác nhau. Ví dụ, chúng ta có thể ghép một bộ mã hóa lớn với một bộ giải mã nhỏ (ví dụ: bộ mã hóa 9B với bộ giải mã 2B) để tạo ra một mô hình “không cân bằng”. Điều này cho phép chúng tôi tinh chỉnh sự đánh đổi giữa chất lượng và hiệu quả cho các tác vụ cụ thể, như tóm tắt, nơi việc hiểu sâu đầu vào quan trọng hơn độ phức tạp của đầu ra được tạo ra.
Hướng tới sự cân bằng tốt hơn giữa chất lượng và hiệu quả
T5Gemma hoạt động như thế nào?
Trong các thử nghiệm của chúng tôi, các mô hình T5Gemma đạt được hiệu suất tương đương hoặc tốt hơn các đối tác Gemma chỉ có bộ giải mã, gần như thống trị đường cong Pareto về chất lượng-hiệu quả suy luận trên nhiều điểm chuẩn, chẳng hạn như SuperGLUE, thước đo chất lượng của biểu diễn đã học được.
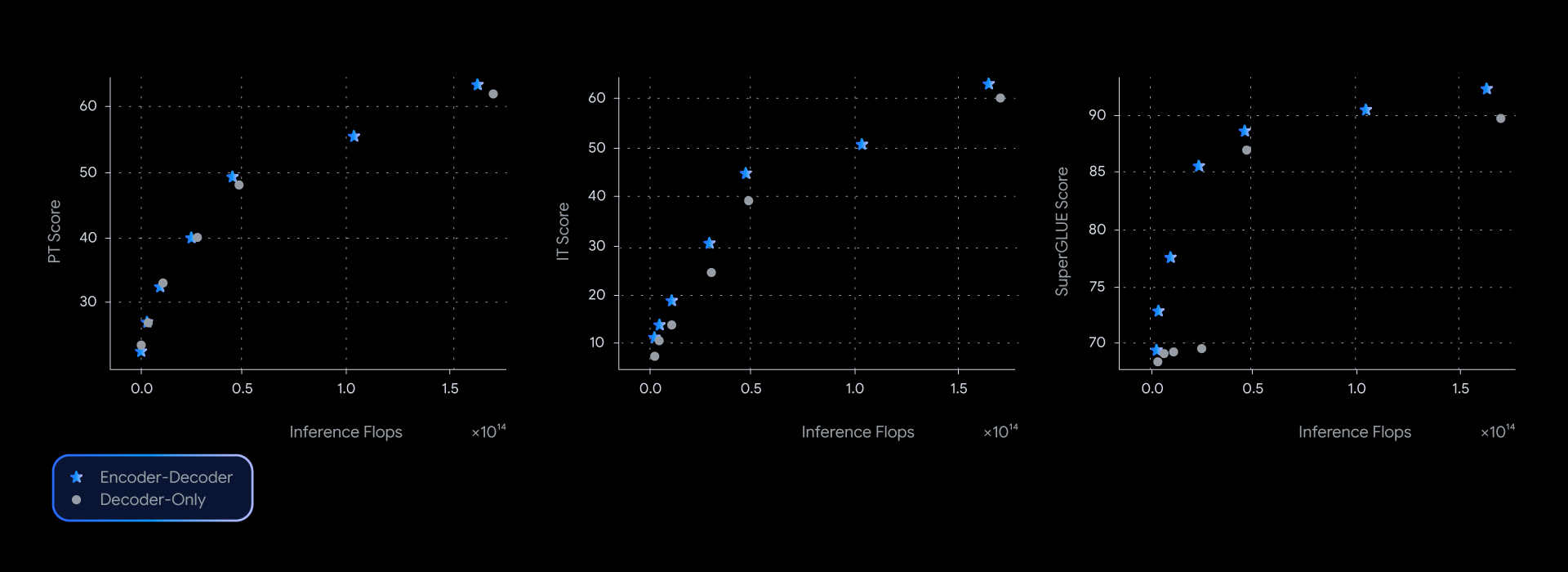 Các mô hình encoder-decoder luôn mang lại hiệu suất tốt hơn cho một mức độ tính toán suy luận nhất định, dẫn đầu đường cong chất lượng-hiệu quả trên một loạt các điểm chuẩn.
Các mô hình encoder-decoder luôn mang lại hiệu suất tốt hơn cho một mức độ tính toán suy luận nhất định, dẫn đầu đường cong chất lượng-hiệu quả trên một loạt các điểm chuẩn.
Ưu điểm về hiệu suất này không chỉ mang tính lý thuyết; nó còn thể hiện chất lượng và tốc độ thực tế. Khi đo độ trễ thực tế cho GSM8K (lập luận toán học), T5Gemma đã giành chiến thắng rõ ràng. Ví dụ, T5Gemma 9B-9B đạt độ chính xác cao hơn Gemma 2 9B nhưng với độ trễ tương tự. Ấn tượng hơn nữa, T5Gemma 9B-2B mang lại sự cải thiện đáng kể về độ chính xác so với mô hình 2B-2B, nhưng độ trễ của nó gần như tương đương với mô hình Gemma 2 2B nhỏ hơn nhiều. Cuối cùng, các thử nghiệm này cho thấy rằng việc thích ứng kiến trúc encoder-decoder mang đến một cách linh hoạt, mạnh mẽ để cân bằng giữa chất lượng và tốc độ suy luận.
Mở khóa các khả năng cơ bản và tinh chỉnh
Liệu LLM encoder-decoder có thể có khả năng tương tự như mô hình chỉ có bộ giải mã không?
Có, T5Gemma thể hiện các khả năng đầy hứa hẹn cả trước và sau khi tinh chỉnh theo hướng dẫn.
Sau quá trình tiền huấn luyện, T5Gemma đạt được những cải thiện ấn tượng trên các tác vụ phức tạp đòi hỏi suy luận. Ví dụ, T5Gemma 9B-9B đạt điểm cao hơn hơn 9 điểm trên GSM8K (lập luận toán học) và cao hơn 4 điểm trên DROP (hiểu văn bản) so với mô hình Gemma 2 9B gốc. Mô hình này chứng minh rằng kiến trúc encoder-decoder, khi được khởi tạo thông qua thích ứng, có tiềm năng tạo ra một mô hình cơ bản có khả năng và hiệu suất cao hơn.
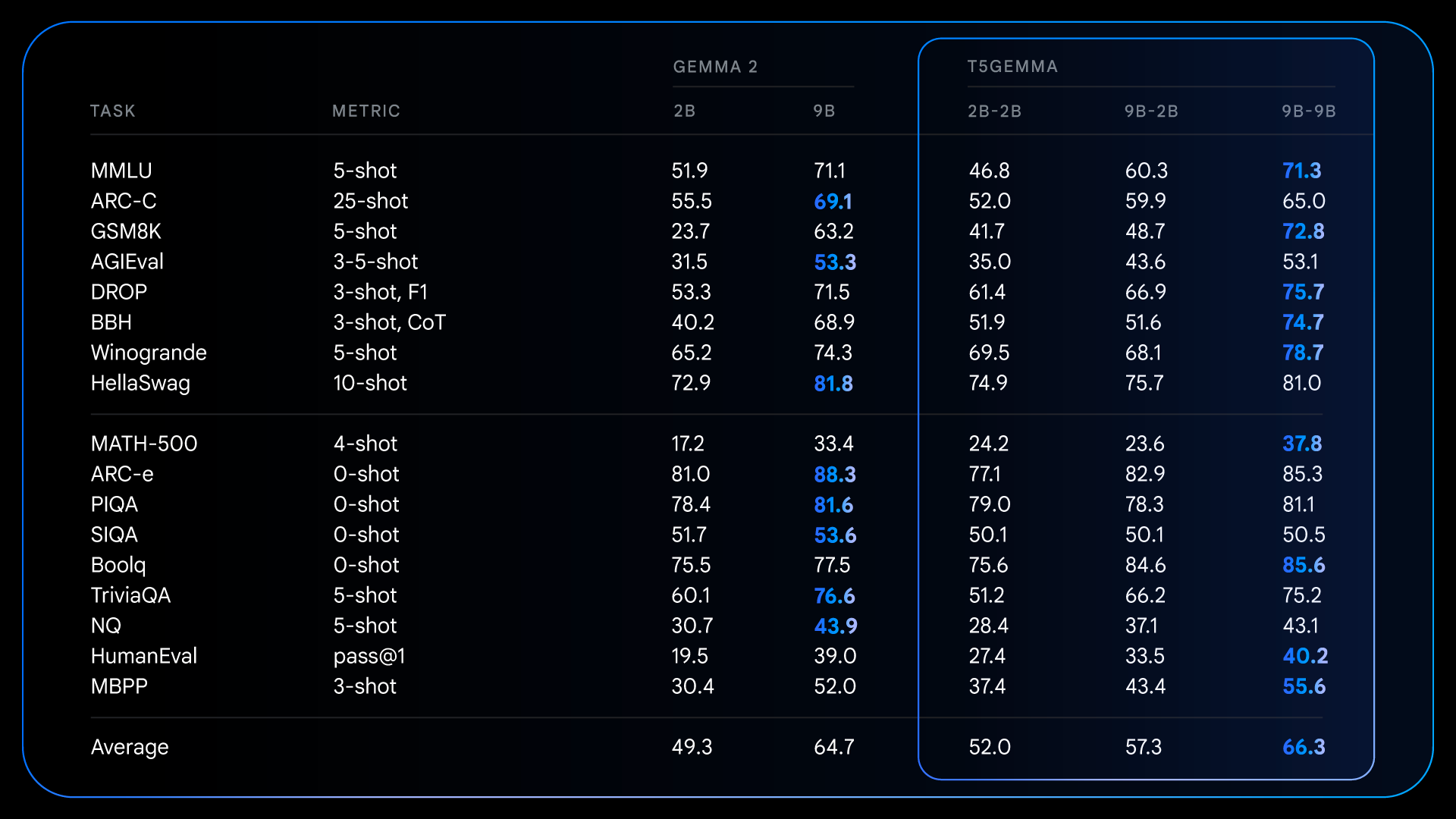 Kết quả chi tiết cho các mô hình đã huấn luyện trước, minh họa cách các mô hình thích ứng có những cải thiện đáng kể trên một số điểm chuẩn đòi hỏi suy luận so với Gemma 2 chỉ có bộ giải mã.
Kết quả chi tiết cho các mô hình đã huấn luyện trước, minh họa cách các mô hình thích ứng có những cải thiện đáng kể trên một số điểm chuẩn đòi hỏi suy luận so với Gemma 2 chỉ có bộ giải mã.
Những cải tiến cơ bản từ quá trình tiền huấn luyện này tạo nền tảng cho những cải thiện thậm chí còn ấn tượng hơn sau khi tinh chỉnh theo hướng dẫn. Ví dụ, khi so sánh Gemma 2 IT với T5Gemma IT, khoảng cách về hiệu suất tăng lên đáng kể trên diện rộng. T5Gemma 2B-2B IT chứng kiến điểm MMLU của nó tăng gần 12 điểm so với Gemma 2 2B, và điểm GSM8K của nó tăng từ 58.0% lên 70.7%. Kiến trúc thích ứng không chỉ cung cấp một điểm khởi đầu tốt hơn mà còn phản ứng hiệu quả hơn với quá trình tinh chỉnh theo hướng dẫn, cuối cùng dẫn đến một mô hình cuối cùng có khả năng và hữu ích hơn đáng kể.
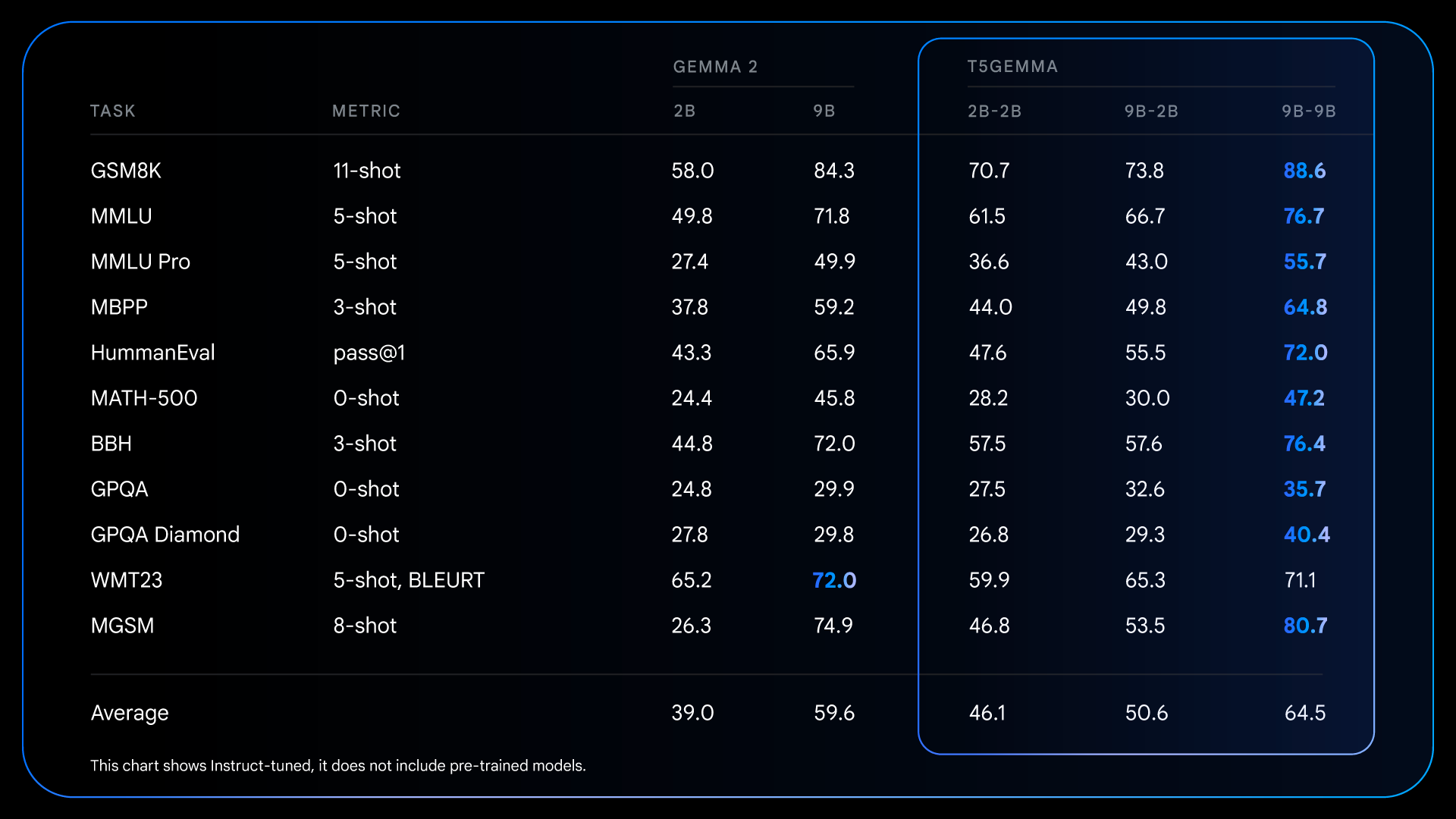 Kết quả chi tiết cho các mô hình đã tinh chỉnh + RLHFed, minh họa khả năng của quá trình hậu huấn luyện để khuếch đại đáng kể những lợi thế về hiệu suất của kiến trúc encoder-decoder.
Kết quả chi tiết cho các mô hình đã tinh chỉnh + RLHFed, minh họa khả năng của quá trình hậu huấn luyện để khuếch đại đáng kể những lợi thế về hiệu suất của kiến trúc encoder-decoder.
Khám phá mô hình của chúng tôi: Phát hành các checkpoint T5Gemma
Chúng tôi rất vui mừng giới thiệu phương pháp mới này để xây dựng các mô hình encoder-decoder mạnh mẽ, đa dụng bằng cách thích ứng từ các LLM chỉ có bộ giải mã đã được huấn luyện trước như Gemma 2. Để giúp đẩy nhanh nghiên cứu sâu hơn và cho phép cộng đồng xây dựng dựa trên công trình này, chúng tôi vui mừng phát hành một bộ các checkpoint T5Gemma của mình.
Bản phát hành bao gồm:
- Nhiều kích thước: Các checkpoint cho các mô hình cỡ T5 (Small, Base, Large và XL), các mô hình dựa trên Gemma 2 (2B và 9B), cũng như một mô hình bổ sung nằm giữa T5 Large và T5 XL.
- Nhiều biến thể: Các mô hình đã huấn luyện trước và tinh chỉnh theo hướng dẫn.
- Cấu hình linh hoạt: Một checkpoint 9B-2B mạnh mẽ và hiệu quả không cân bằng để khám phá sự đánh đổi giữa kích thước bộ mã hóa và bộ giải mã.
- Các mục tiêu huấn luyện khác nhau: Các mô hình được huấn luyện với mục tiêu PrefixLM hoặc UL2 để mang lại hiệu suất sinh văn bản tiên tiến hoặc chất lượng biểu diễn tốt nhất.
Chúng tôi hy vọng các checkpoint này sẽ cung cấp một nguồn tài nguyên quý giá để điều tra kiến trúc mô hình, hiệu quả và hiệu suất.
Bắt đầu với T5Gemma
Chúng tôi rất mong chờ xem bạn sẽ xây dựng gì với T5Gemma. Vui lòng tham khảo các liên kết sau để biết thêm thông tin:
- Tìm hiểu về nghiên cứu đằng sau dự án này bằng cách đọc bài báo.
- Tải xuống các mô hình: Tìm trọng số mô hình trên Hugging Face và Kaggle.
- Khám phá khả năng của mô hình hoặc tinh chỉnh chúng cho các trường hợp sử dụng của riêng bạn với Colab notebook.
- Thực hiện suy luận với các mô hình trên Vertex AI.