VaultGemma- LLM riêng tư khác biệt có khả năng nhất thế giới
Mô hình
- 13 min read

VaultGemma: Mô hình ngôn ngữ có khả năng mạnh nhất với sự riêng tư vi phân
Giới thiệu về VaultGemma
Trí tuệ nhân tạo (AI) ngày càng tích hợp sâu hơn vào cuộc sống của chúng ta, việc xây dựng AI với sự riêng tư làm cốt lõi là một bước tiến quan trọng. Quyền riêng tư vi phân (Differential Privacy - DP) cung cấp một giải pháp mạnh mẽ về mặt toán học bằng cách thêm nhiễu có hiệu chỉnh để ngăn chặn việc ghi nhớ dữ liệu.
Tuy nhiên, việc áp dụng DP cho các Mô hình Ngôn ngữ Lớn (LLM) đặt ra những thách thức. Áp lực của nhiễu DP làm thay đổi các quy luật tỷ lệ (scaling laws) truyền thống – các quy tắc mô tả động lực hiệu suất – bằng cách làm giảm sự ổn định trong quá trình huấn luyện và tăng đáng kể kích thước lô (batch size) cùng chi phí tính toán.
Nghiên cứu mới của chúng tôi, “Scaling Laws for Differentially Private Language Models”, được thực hiện với sự hợp tác của Google DeepMind, đã thiết lập các quy luật mô hình hóa chính xác những phức tạp này, cung cấp một bức tranh toàn diện về sự đánh đổi giữa tính toán, quyền riêng tư và tiện ích. Dựa trên nghiên cứu này, chúng tôi vui mừng giới thiệu VaultGemma, mô hình lớn nhất (1 tỷ tham số) được huấn luyện từ đầu với quyền riêng tư vi phân. Chúng tôi công bố trọng số trên Hugging Face và Kaggle, cùng với một báo cáo kỹ thuật, nhằm thúc đẩy sự phát triển của thế hệ AI riêng tư tiếp theo.
Hiểu rõ các quy luật tỷ lệ
Với phương pháp thử nghiệm được xây dựng cẩn thận, chúng tôi đã định lượng lợi ích của việc tăng kích thước mô hình, kích thước lô và số lần lặp trong bối cảnh huấn luyện DP. Công việc của chúng tôi đòi hỏi phải đưa ra một số giả định đơn giản hóa để khắc phục số lượng kết hợp khổng lồ có thể được xem xét. Chúng tôi giả định rằng mức độ mô hình học được phụ thuộc chủ yếu vào “tỷ lệ nhiễu-lô” (noise-batch ratio), so sánh lượng nhiễu ngẫu nhiên chúng tôi thêm vào cho quyền riêng tư với kích thước của các nhóm dữ liệu (lô) mà chúng tôi sử dụng để huấn luyện. Giả định này có hiệu lực vì nhiễu quyền riêng tư chúng tôi thêm vào lớn hơn nhiều so với bất kỳ sự ngẫu nhiên tự nhiên nào đến từ việc lấy mẫu dữ liệu.
Để thiết lập một quy luật tỷ lệ DP, chúng tôi đã thực hiện một loạt các thử nghiệm toàn diện để đánh giá hiệu suất trên nhiều kích thước mô hình và tỷ lệ nhiễu-lô khác nhau. Dữ liệu thực nghiệm thu được, cùng với các mối quan hệ xác định đã biết giữa các biến số khác, cho phép chúng tôi trả lời nhiều truy vấn theo kiểu quy luật tỷ lệ thú vị, chẳng hạn như: “Với ngân sách tính toán, ngân sách quyền riêng tư và ngân sách dữ liệu nhất định, cấu hình huấn luyện tối ưu để đạt được tổn thất huấn luyện thấp nhất có thể là gì?”

Cấu trúc các quy luật tỷ lệ DP. Chúng tôi thiết lập rằng tổn thất dự đoán có thể được mô hình hóa chính xác bằng cách chủ yếu sử dụng kích thước mô hình, số lần lặp và tỷ lệ nhiễu-lô, đơn giản hóa các tương tác phức tạp giữa ngân sách tính toán, quyền riêng tư và dữ liệu.
Phát hiện chính: Sức mạnh cộng hưởng
Trước khi đi sâu vào các quy luật tỷ lệ đầy đủ, điều hữu ích là hiểu động lực và sự cộng hưởng giữa ngân sách tính toán, ngân sách quyền riêng tư và ngân sách dữ liệu từ góc độ kế toán quyền riêng tư — tức là hiểu các yếu tố này ảnh hưởng đến tỷ lệ nhiễu-lô như thế nào đối với kích thước mô hình và số lần lặp cố định. Phân tích này có chi phí thấp hơn vì nó không yêu cầu bất kỳ quá trình huấn luyện mô hình nào, nhưng vẫn mang lại nhiều hiểu biết hữu ích. Ví dụ, việc tăng ngân sách quyền riêng tư một cách riêng biệt dẫn đến lợi ích giảm dần, trừ khi nó đi kèm với sự gia tăng tương ứng về ngân sách tính toán (FLOPs) hoặc ngân sách dữ liệu (tokens).
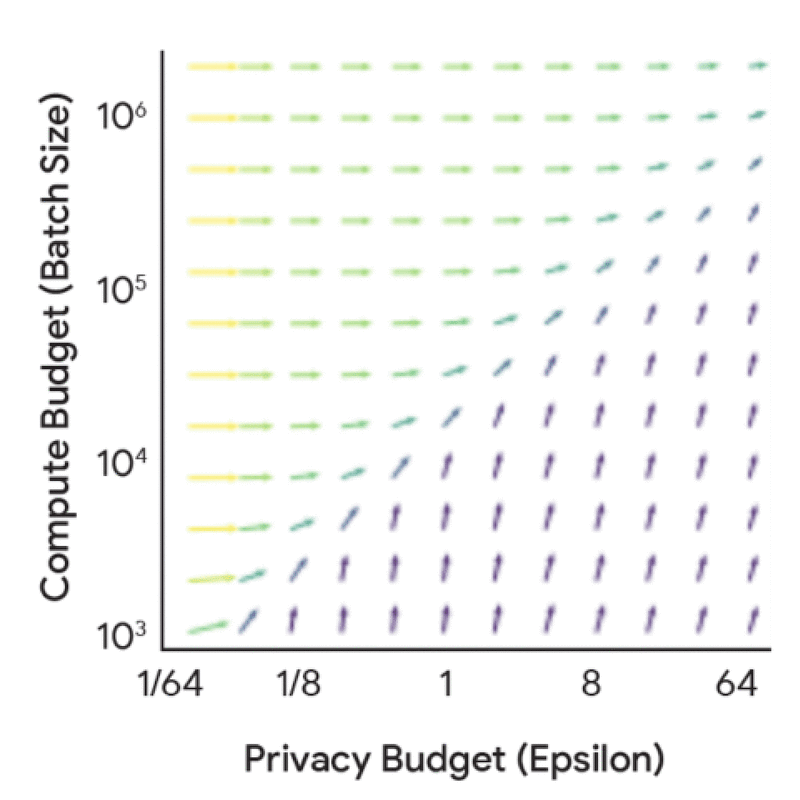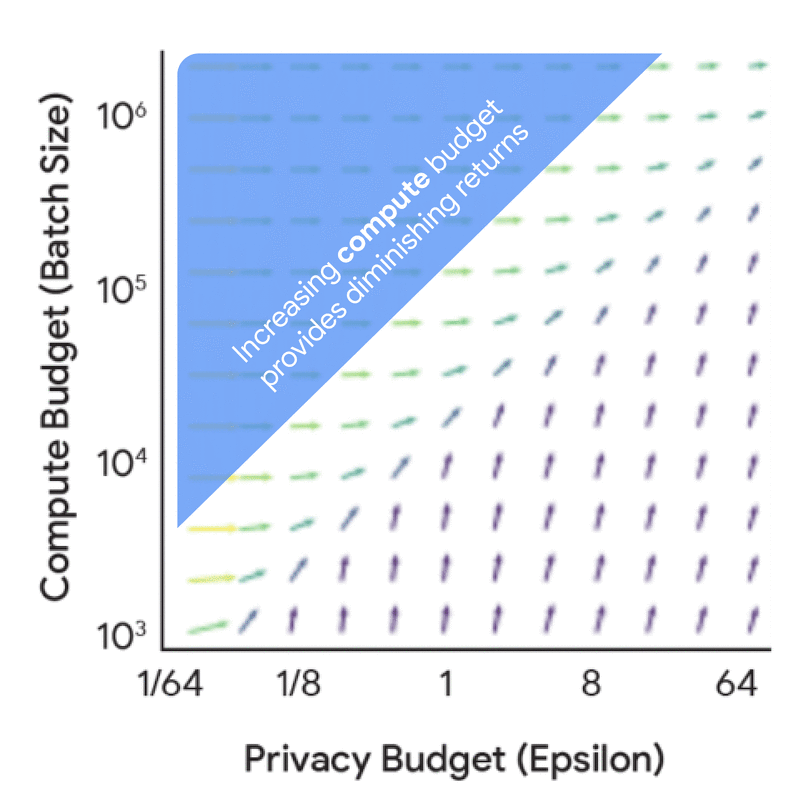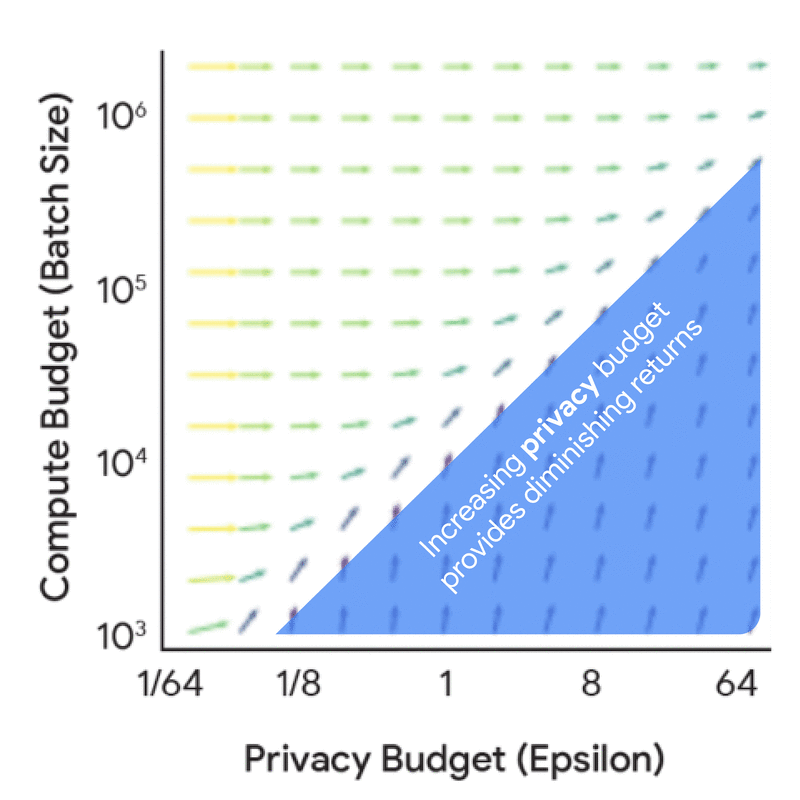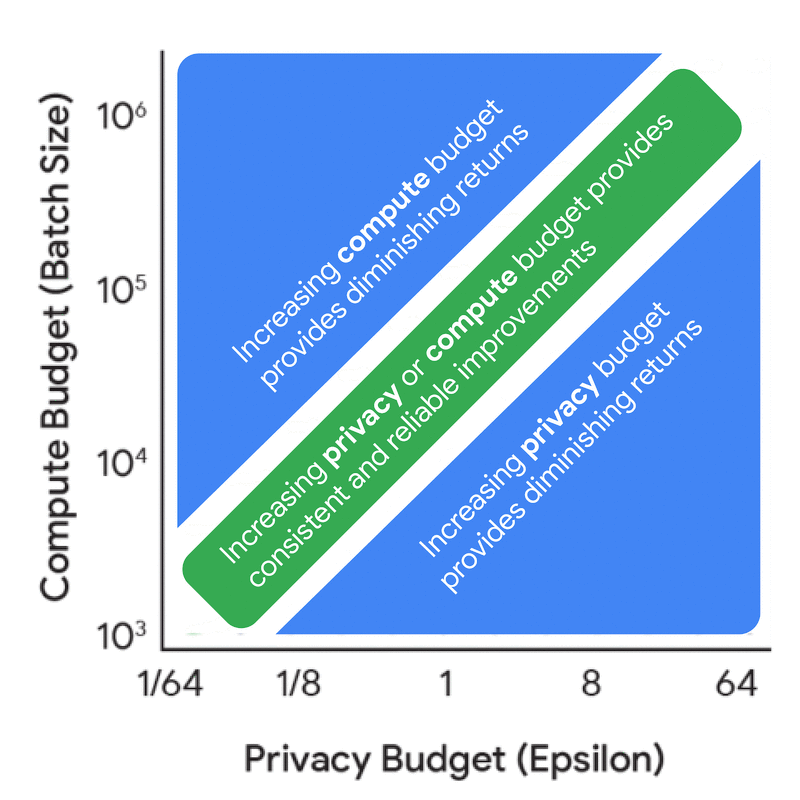
Lợi ích biên của việc tăng ngân sách quyền riêng tư (epsilon) và ngân sách tính toán (kích thước lô) về tác động của chúng đến tỷ lệ nhiễu-lô.
Để khám phá sâu hơn về sự cộng hưởng này, hình ảnh trực quan dưới đây cho thấy cấu hình huấn luyện tối ưu thay đổi như thế nào dựa trên các ràng buộc khác nhau. Khi ngân sách quyền riêng tư và tính toán thay đổi, hãy lưu ý cách khuyến nghị chuyển đổi giữa việc đầu tư vào một mô hình nhỏ hơn so với việc huấn luyện với kích thước lô lớn hơn hoặc nhiều lần lặp hơn.

Dự đoán tổn thất huấn luyện cho các cài đặt khác nhau của ngân sách dữ liệu/quyền riêng tư/tính toán, và phân tích chi tiết hơn theo số lần lặp, kích thước lô và kích thước mô hình. Các biểu đồ cho thấy cả tổn thất tối thiểu có thể đạt được cho các cài đặt ngân sách khác nhau, cũng như các cấu hình siêu tham số tối ưu.
Dữ liệu này cung cấp một nguồn thông tin hữu ích cho các nhà thực hành. Mặc dù tất cả các hiểu biết đều được báo cáo trong bài báo, một phát hiện quan trọng là nên huấn luyện một mô hình nhỏ hơn nhiều với kích thước lô lớn hơn nhiều so với những gì sẽ được sử dụng nếu không có DP. Hiểu biết chung này không gây ngạc nhiên cho các chuyên gia DP, do tầm quan trọng của kích thước lô lớn. Mặc dù hiểu biết chung này vẫn giữ nguyên trong nhiều cài đặt, các cấu hình huấn luyện tối ưu thực sự thay đổi theo ngân sách quyền riêng tư và dữ liệu. Hiểu rõ sự đánh đổi là rất quan trọng để đảm bảo cả ngân sách tính toán và quyền riêng tư đều được sử dụng một cách khôn ngoan trong các tình huống huấn luyện thực tế. Các hình ảnh trực quan trên cũng cho thấy rằng thường có sự linh hoạt trong các cấu hình huấn luyện — tức là, một loạt các kích thước mô hình có thể cung cấp tiện ích rất giống nhau nếu được kết hợp với số lần lặp và/hoặc kích thước lô phù hợp.
Áp dụng quy luật tỷ lệ để xây dựng VaultGemma
Các mô hình Gemma được thiết kế với trách nhiệm và an toàn làm cốt lõi. Điều này làm cho chúng trở thành một nền tảng tự nhiên để phát triển một mô hình chất lượng sản xuất, được huấn luyện DP như VaultGemma.
Tiến bộ thuật toán: Huấn luyện ở quy mô lớn
Các quy luật tỷ lệ chúng tôi đã rút ra ở trên đại diện cho bước đầu tiên quan trọng để huấn luyện một mô hình Gemma hữu ích với DP. Chúng tôi đã sử dụng các quy luật tỷ lệ để xác định cả lượng tính toán chúng tôi cần để huấn luyện một mô hình Gemma 2 dựa trên tham số 1B tối ưu về tính toán với DP, và cách phân bổ lượng tính toán đó giữa kích thước lô, số lần lặp và độ dài chuỗi để đạt được tiện ích tốt nhất.
Một khoảng trống nổi bật giữa nghiên cứu làm nền tảng cho các quy luật tỷ lệ và việc huấn luyện thực tế VaultGemma là cách chúng tôi xử lý lấy mẫu Poisson (Poisson sampling), một thành phần trung tâm của DP-SGD. Ban đầu, chúng tôi sử dụng một phương pháp đơn giản là tải dữ liệu theo các lô đồng nhất, sau đó chuyển sang lấy mẫu Poisson để có được đảm bảo quyền riêng tư tốt nhất với lượng nhiễu ít nhất. Phương pháp này đặt ra hai thách thức chính: nó tạo ra các lô có kích thước khác nhau và nó yêu cầu một thứ tự xử lý dữ liệu ngẫu nhiên, cụ thể. Chúng tôi đã giải quyết điều này bằng cách sử dụng công trình gần đây của chúng tôi về Scalable DP-SGD, cho phép chúng tôi xử lý dữ liệu theo các lô có kích thước cố định — bằng cách thêm phần đệm bổ sung hoặc cắt bớt chúng — trong khi vẫn duy trì các biện pháp bảo vệ quyền riêng tư mạnh mẽ.
Kết quả
Trang bị các quy luật tỷ lệ mới và các thuật toán huấn luyện nâng cao, chúng tôi đã xây dựng VaultGemma, cho đến nay là mô hình mở lớn nhất (1 tỷ tham số) được huấn luyện đầy đủ với quyền riêng tư vi phân với một phương pháp có thể mang lại các mô hình có tiện ích cao.
Từ quá trình huấn luyện VaultGemma, chúng tôi nhận thấy các quy luật tỷ lệ của mình có độ chính xác cao. Tổn thất huấn luyện cuối cùng của VaultGemma rất gần với những gì các phương trình của chúng tôi dự đoán, xác nhận nghiên cứu của chúng tôi và cung cấp cho cộng đồng một lộ trình đáng tin cậy cho sự phát triển mô hình riêng tư trong tương lai.

So sánh hiệu suất của VaultGemma 1B (có quyền riêng tư vi phân) so với đối tác không có quyền riêng tư (Gemma3 1B) và một mô hình cơ sở cũ hơn (GPT-2 1.5B). Kết quả định lượng mức đầu tư tài nguyên hiện tại cần thiết cho quyền riêng tư và cho thấy rằng quá trình huấn luyện DP hiện đại mang lại tiện ích tương đương với các mô hình không có quyền riêng tư từ khoảng năm năm trước, làm nổi bật khoảng cách quan trọng mà công việc của chúng tôi sẽ giúp cộng đồng thu hẹp một cách có hệ thống.
Chúng tôi cũng so sánh hiệu suất hạ nguồn của mô hình của chúng tôi với đối tác không có quyền riêng tư trên một loạt các tiêu chuẩn học thuật (tức là HellaSwag, BoolQ, PIQA, SocialIQA, TriviaQA, ARC-C, ARC-E). Để đặt hiệu suất này vào bối cảnh và định lượng mức đầu tư tài nguyên hiện tại cần thiết cho quyền riêng tư, chúng tôi cũng đưa ra so sánh với một mô hình GPT-2 cũ hơn có kích thước tương tự, mô hình này hoạt động tương tự trên các tiêu chuẩn này. So sánh này cho thấy rằng các phương pháp huấn luyện riêng tư ngày nay tạo ra các mô hình có tiện ích tương đương với các mô hình không có quyền riêng tư từ khoảng 5 năm trước, làm nổi bật khoảng cách quan trọng mà công việc của chúng tôi sẽ giúp cộng đồng thu hẹp một cách có hệ thống.
Cuối cùng, mô hình đi kèm với các biện pháp bảo vệ quyền riêng tư lý thuyết và thực nghiệm mạnh mẽ.
Đảm bảo quyền riêng tư chính thức
Nói chung, cả các tham số quyền riêng tư (ε, δ) và đơn vị quyền riêng tư (privacy unit) đều là những yếu tố quan trọng cần xem xét khi thực hiện huấn luyện DP, vì chúng cùng nhau xác định mô hình đã huấn luyện có thể học được những gì. VaultGemma đã được huấn luyện với đảm bảo DP ở cấp độ chuỗi (sequence-level) là (ε ≤ 2.0, δ ≤ 1.1e-10), trong đó một chuỗi bao gồm 1024 token liên tiếp được trích xuất từ các nguồn dữ liệu không đồng nhất. Cụ thể, chúng tôi đã sử dụng cùng một hỗn hợp huấn luyện đã được sử dụng để huấn luyện mô hình Gemma 2, bao gồm một số lượng tài liệu có độ dài khác nhau. Trong quá trình tiền xử lý, các tài liệu dài được chia nhỏ và mã hóa thành nhiều chuỗi, và các tài liệu ngắn hơn được đóng gói lại thành một chuỗi duy nhất. Mặc dù đơn vị quyền riêng tư cấp độ chuỗi là một lựa chọn tự nhiên cho hỗn hợp huấn luyện của chúng tôi, trong các tình huống có ánh xạ rõ ràng giữa dữ liệu và người dùng, quyền riêng tư vi phân cấp độ người dùng sẽ là một lựa chọn tốt hơn.
Điều này có ý nghĩa gì trong thực tế? Nói một cách không chính thức, vì chúng tôi cung cấp sự bảo vệ ở cấp độ chuỗi, nếu thông tin liên quan đến bất kỳ sự kiện hoặc suy luận nào (có khả năng riêng tư) xảy ra trong một chuỗi duy nhất, thì về cơ bản VaultGemma không biết sự kiện đó: phản hồi cho bất kỳ truy vấn nào sẽ tương tự về mặt thống kê với kết quả từ một mô hình chưa bao giờ huấn luyện trên chuỗi được đề cập. Tuy nhiên, nếu nhiều chuỗi huấn luyện chứa thông tin liên quan đến một sự kiện cụ thể, thì nói chung VaultGemma sẽ có thể cung cấp thông tin đó.
Ghi nhớ thực nghiệm
Để bổ sung cho đảm bảo DP cấp độ chuỗi của chúng tôi, chúng tôi đã tiến hành các bài kiểm tra bổ sung về các thuộc tính quyền riêng tư thực nghiệm của mô hình đã huấn luyện. Để thực hiện điều này, chúng tôi đã nhắc mô hình bằng một tiền tố gồm 50 token từ một tài liệu huấn luyện để xem liệu nó có tạo ra hậu tố tương ứng gồm 50 token hay không. VaultGemma 1B không cho thấy bất kỳ sự ghi nhớ có thể phát hiện nào về dữ liệu huấn luyện của nó và chứng minh thành công hiệu quả của quá trình huấn luyện DP.
Kết luận
VaultGemma đại diện cho một bước tiến quan trọng trong hành trình xây dựng AI vừa mạnh mẽ vừa có quyền riêng tư theo thiết kế. Bằng cách phát triển và áp dụng sự hiểu biết mới, mạnh mẽ về các quy luật tỷ lệ cho DP, chúng tôi đã huấn luyện và phát hành thành công mô hình ngôn ngữ lớn nhất, mở, được huấn luyện bằng DP cho đến nay.
Mặc dù vẫn còn một khoảng cách về tiện ích giữa các mô hình được huấn luyện bằng DP và các mô hình không được huấn luyện bằng DP, chúng tôi tin rằng khoảng cách này có thể được thu hẹp một cách có hệ thống bằng nhiều nghiên cứu hơn về thiết kế cơ chế cho huấn luyện DP. Chúng tôi hy vọng rằng VaultGemma và nghiên cứu đi kèm của chúng tôi sẽ trao quyền cho cộng đồng để xây dựng thế hệ AI an toàn, có trách nhiệm và riêng tư tiếp theo cho mọi người.
Lời cảm ơn
Chúng tôi muốn cảm ơn toàn bộ đội ngũ Gemma và Google Privacy vì những đóng góp và hỗ trợ của họ trong suốt dự án này, đặc biệt là Peter Kairouz, Brendan McMahan và Dan Ramage đã góp ý về bài đăng blog, Mark Simborg và Kimberly Schwede đã hỗ trợ trực quan hóa, và các đội ngũ tại Google đã hỗ trợ thiết kế thuật toán, triển khai cơ sở hạ tầng và bảo trì sản xuất. Những người sau đây đã đóng góp trực tiếp vào công trình được trình bày ở đây (sắp xếp theo thứ tự bảng chữ cái): Borja Balle, Zachary Charles, Christopher A. Choquette-Choo, Lynn Chua, Prem Eruvbetine, Badih Ghazi, Steve He, Yangsibo Huang, Armand Joulin, George Kaissis, Pritish Kamath, Ravi Kumar, Daogao Liu, Ruibo Liu, Pasin Manurangsi, Thomas Mesnard, Andreas Terzis, Tris Warkentin, Da Yu và Chiyuan Zhang.
Nhãn: AI tạo sinh, Mô hình & Bộ dữ liệu nguồn mở, AI có trách nhiệm, Bảo mật, Quyền riêng tư và Phòng chống lạm dụng
Link bài viết gốc
- Tags:
- Ai
- September 2025
- Research.google