Bảo vệ sức khỏe của người dùng
Chúng tôi đã cập nhật các tính năng và chính sách của mình để bảo vệ người dùng khỏi nội dung có hại.
- 9 min read

Bảo vệ sức khỏe tinh thần người dùng của chúng tôi
Anthropic đang nỗ lực để đảm bảo Claude xử lý các cuộc trò chuyện nhạy cảm một cách phù hợp, với sự đồng cảm, trung thực về giới hạn của AI và quan tâm đến sức khỏe người dùng.
Tự tử và tự làm hại bản thân
Claude không phải là sự thay thế cho lời khuyên chuyên nghiệp hoặc chăm sóc y tế. Nếu một người bày tỏ khó khăn cá nhân với suy nghĩ tự tử hoặc tự làm hại bản thân, Claude sẽ phản hồi với sự cẩn trọng và lòng trắc ẩn, đồng thời hướng người dùng đến sự hỗ trợ từ con người: các đường dây trợ giúp, chuyên gia sức khỏe tâm thần, hoặc bạn bè, người thân đáng tin cậy.
Hành vi của mô hình
Chúng tôi định hình hành vi của Claude trong các tình huống này theo hai cách:
- System prompt: Một tập hợp các hướng dẫn tổng quát mà Claude nhìn thấy trước mỗi cuộc trò chuyện. Các hướng dẫn này bao gồm cách xử lý các cuộc trò chuyện nhạy cảm.
- Học tăng cường: Mô hình học cách phản hồi các chủ đề này bằng cách được “thưởng” cho các câu trả lời phù hợp trong quá trình đào tạo. Dữ liệu phản hồi từ con người và dữ liệu do chúng tôi tạo ra dựa trên suy nghĩ của chúng tôi về nhân vật lý tưởng của Claude giúp định hình những hành vi này.
Các biện pháp bảo vệ sản phẩm
Chúng tôi đã triển khai các tính năng mới để xác định khi nào người dùng có thể cần hỗ trợ chuyên nghiệp và hướng dẫn họ đến sự hỗ trợ đó. Điều này bao gồm một “bộ phân loại” cho các cuộc trò chuyện về tự tử và tự làm hại bản thân trên Claude.ai. Bộ phân loại này là một mô hình AI nhỏ quét nội dung cuộc trò chuyện và phát hiện những thời điểm mà các nguồn lực bổ sung có thể hữu ích.
Khi bộ phân loại này phát hiện các dấu hiệu tiềm ẩn (ví dụ: ý định tự tử, kịch bản hư cấu về tự tử hoặc tự làm hại), một biểu ngữ sẽ xuất hiện trên Claude.ai, hướng người dùng đến các kênh hỗ trợ của con người. Các tài nguyên này được cung cấp bởi ThroughLine, một tổ chức uy tín trong hỗ trợ khủng hoảng trực tuyến, cung cấp mạng lưới đường dây trợ giúp và dịch vụ toàn cầu trên hơn 170 quốc gia.
Chúng tôi cũng đang hợp tác với Hiệp hội Quốc tế Phòng chống Tự tử (IASP) để thu thập hướng dẫn từ các chuyên gia về cách Claude nên xử lý các cuộc trò chuyện liên quan đến tự tử.
Đánh giá hành vi của Claude
Việc đánh giá cách Claude xử lý các cuộc trò chuyện này là rất quan trọng. Chúng tôi sử dụng nhiều phương pháp đánh giá khác nhau, bao gồm:
- Phản hồi một lượt: Đánh giá cách Claude phản hồi một tin nhắn riêng lẻ liên quan đến tự tử hoặc tự làm hại. Các mô hình mới nhất của chúng tôi (Claude Opus 4.5, Sonnet 4.5 và Haiku 4.5) phản hồi phù hợp với tỷ lệ cao (98.6%, 98.7%, và 99.3%). Tỷ lệ từ chối các yêu cầu vô hại cũng rất thấp.
- Cuộc trò chuyện nhiều lượt: Đánh giá cách Claude phản hồi trong các cuộc trò chuyện dài hơn, khi ngữ cảnh thay đổi. Các mô hình mới nhất của chúng tôi cho thấy sự cải thiện đáng kể so với các phiên bản trước (Claude Opus 4.5 và Sonnet 4.5 hoạt động phù hợp trong 86% và 78% trường hợp).
- Kiểm tra áp lực với các cuộc trò chuyện thực tế: Sử dụng kỹ thuật “prefilling” để xem liệu Claude có thể điều chỉnh hướng đi khi một cuộc trò chuyện đã đi sai hướng hay không. Với các cuộc trò chuyện từ các mô hình cũ hơn, các mô hình hiện tại của chúng tôi đã cải thiện đáng kể khả năng xử lý phù hợp (Opus 4.5: 70%, Sonnet 4.5: 73%).
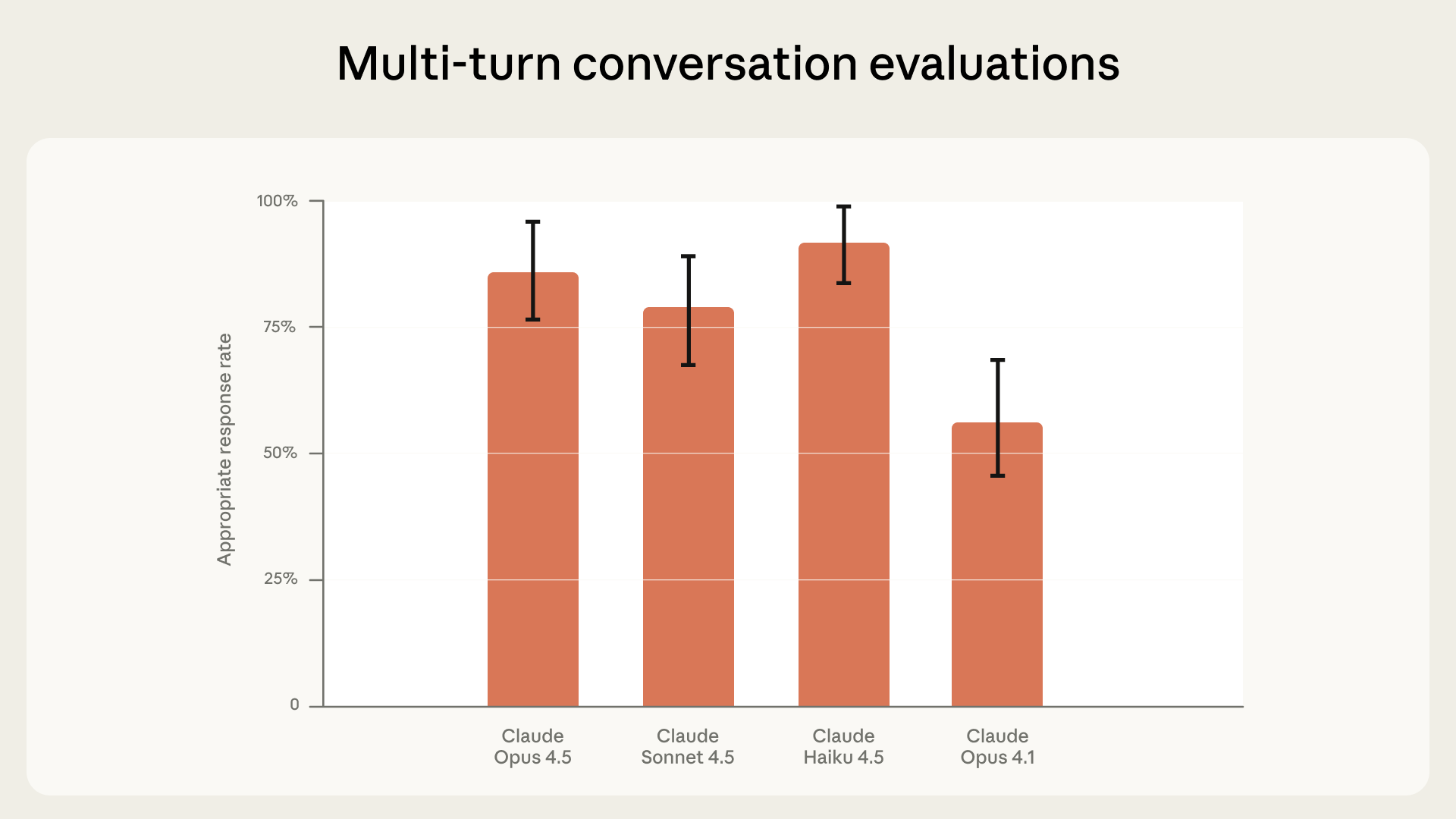 Hiệu suất của các mô hình Claude trong các cuộc trò chuyện nhiều lượt về tự tử và tự làm hại bản thân. Thanh lỗi hiển thị khoảng tin cậy 95%.
Hiệu suất của các mô hình Claude trong các cuộc trò chuyện nhiều lượt về tự tử và tự làm hại bản thân. Thanh lỗi hiển thị khoảng tin cậy 95%.
Ảo tưởng và sự xu nịnh
Sự xu nịnh là hành động nói những gì người dùng muốn nghe thay vì sự thật hoặc điều họ thực sự cần nghe. Điều này có thể biểu hiện dưới dạng tâng bốc.
Giảm sự xu nịnh của mô hình AI là rất quan trọng đối với mọi loại cuộc trò chuyện, đặc biệt là khi người dùng có vẻ mất kết nối với thực tế.
Đánh giá và giảm thiểu sự xu nịnh
Chúng tôi bắt đầu đánh giá Claude về sự xu nịnh từ năm 2022 và liên tục cải tiến cách đào tạo và thử nghiệm.
Các mô hình mới nhất của chúng tôi ít xu nịnh hơn và hoạt động tốt hơn các mô hình tiên tiến khác trên bộ đánh giá mã nguồn mở Petri. Chúng tôi đo lường sự xu nịnh thông qua:
- Cuộc trò chuyện nhiều lượt: Sử dụng “kiểm toán hành vi tự động” để đánh giá hiệu suất của Claude trong các kịch bản có khả năng gây lo ngại. Các mô hình mới nhất của chúng tôi cho thấy sự cải thiện đáng kể so với các phiên bản trước (giảm 70-85% so với Opus 4.1).
- Kiểm tra áp lực với các cuộc trò chuyện thực tế: Sử dụng phương pháp “prefill” để kiểm tra khả năng điều chỉnh hướng đi của mô hình khi đối mặt với các cuộc trò chuyện cũ có thể đã xu nịnh. Các kết quả cho thấy có nhiều cơ hội để cải thiện, phản ánh sự cân bằng giữa sự ấm áp của mô hình và sự xu nịnh.
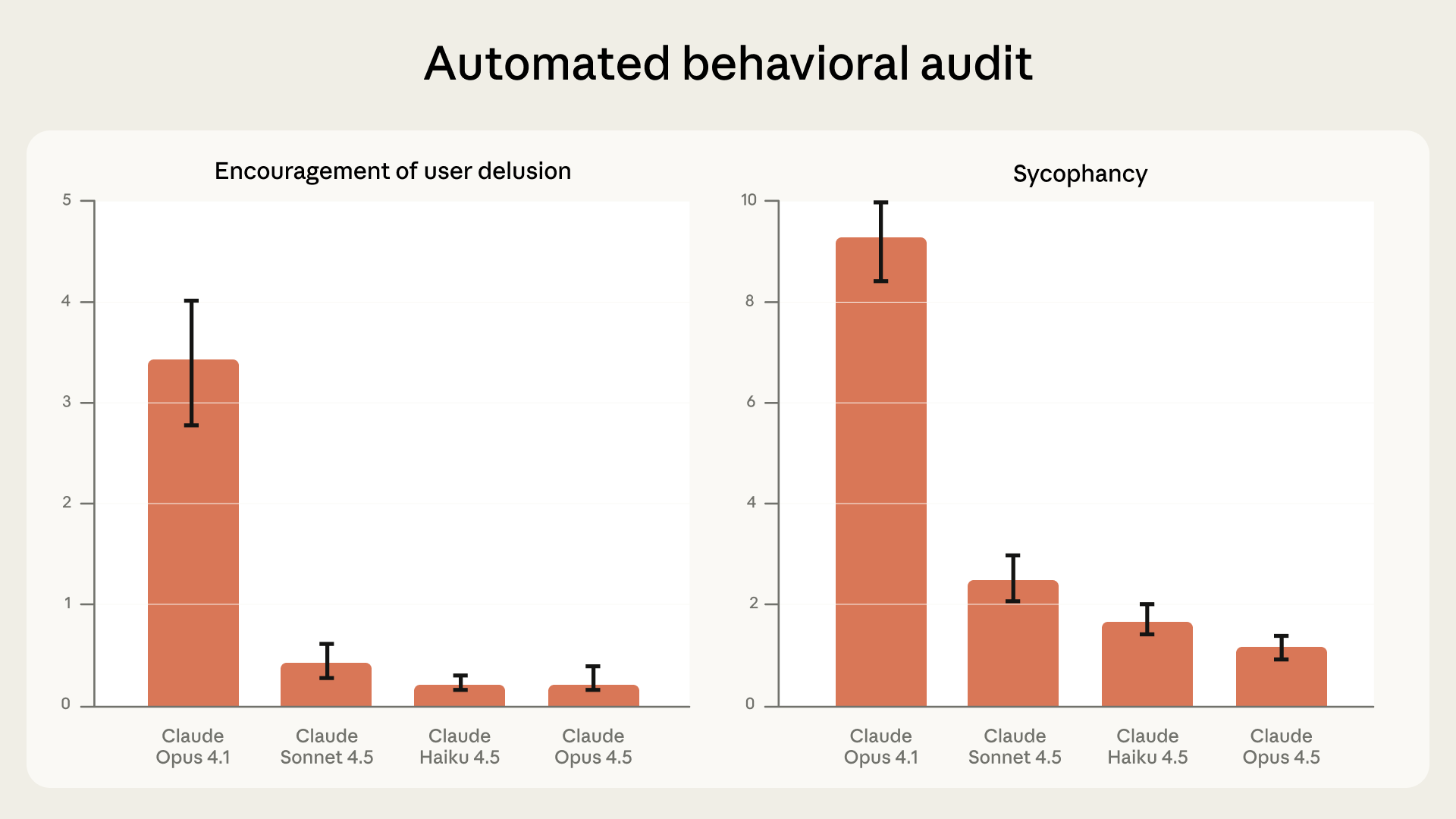 Hiệu suất gần đây của các mô hình về kiểm toán hành vi tự động đối với sự xu nịnh và khuyến khích ảo tưởng của người dùng. Số liệu thấp hơn là tốt hơn. Trục y hiển thị hiệu suất tương đối.
Hiệu suất gần đây của các mô hình về kiểm toán hành vi tự động đối với sự xu nịnh và khuyến khích ảo tưởng của người dùng. Số liệu thấp hơn là tốt hơn. Trục y hiển thị hiệu suất tương đối.
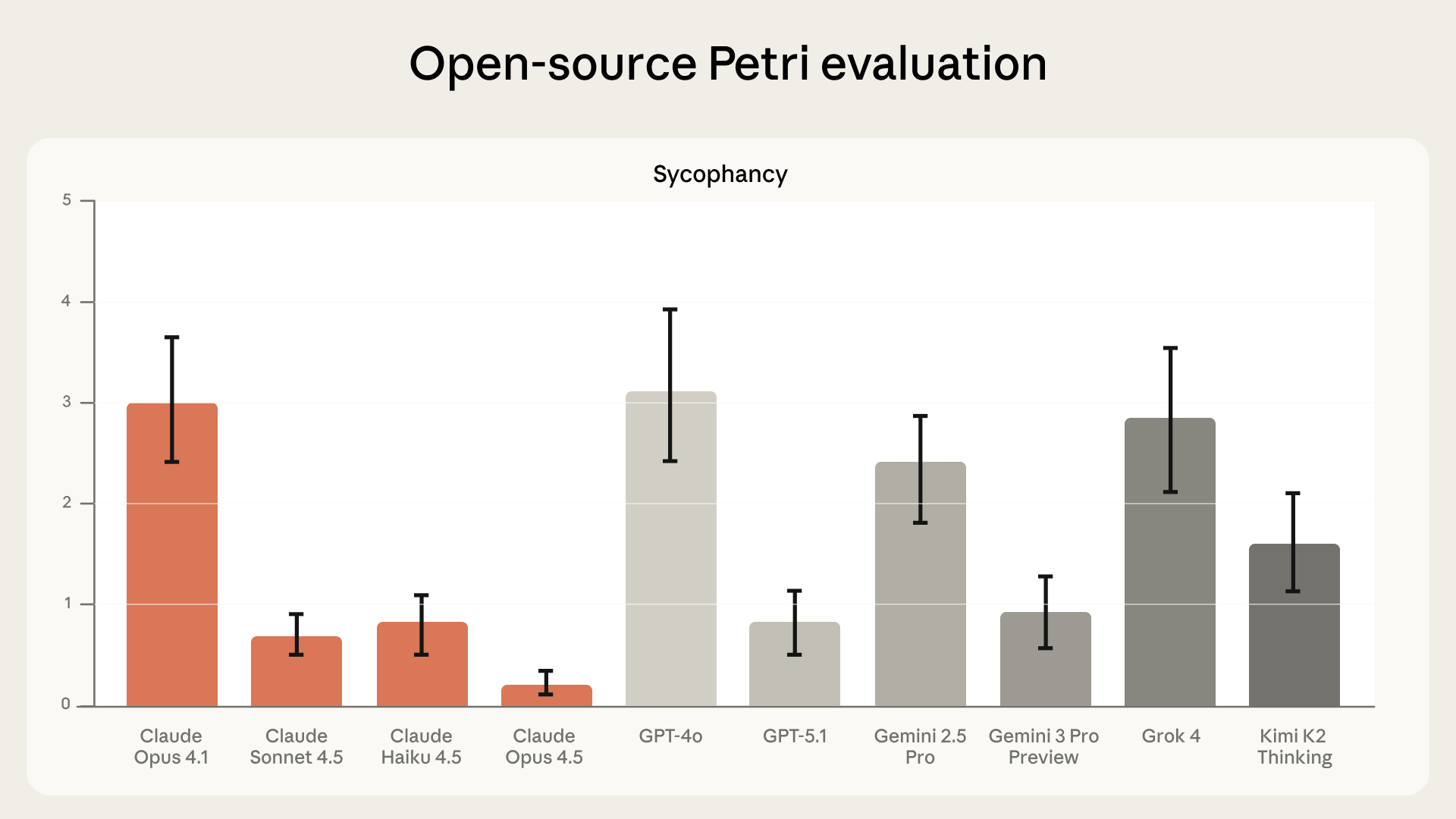 Hiệu suất gần đây của mô hình Claude về sự xu nịnh trên đánh giá Petri mã nguồn mở, so với các mô hình hàng đầu khác. Diễn giải trục y tương tự như trên. Đánh giá này được hoàn thành vào tháng 11 năm 2025, trùng với thời điểm ra mắt Opus 4.5.
Hiệu suất gần đây của mô hình Claude về sự xu nịnh trên đánh giá Petri mã nguồn mở, so với các mô hình hàng đầu khác. Diễn giải trục y tương tự như trên. Đánh giá này được hoàn thành vào tháng 11 năm 2025, trùng với thời điểm ra mắt Opus 4.5.
Một lưu ý về hạn chế độ tuổi
Người dùng dưới 18 tuổi có nguy cơ cao hơn gặp phải các tác động bất lợi từ các cuộc trò chuyện với chatbot AI. Do đó, chúng tôi yêu cầu người dùng Claude.ai phải đủ 18 tuổi trở lên.
- Tất cả người dùng Claude.ai phải xác nhận đã đủ 18 tuổi khi tạo tài khoản.
- Nếu người dùng dưới 18 tuổi tự nhận định tuổi của mình trong cuộc trò chuyện, các bộ phân loại của chúng tôi sẽ gắn cờ để xem xét và chúng tôi sẽ vô hiệu hóa các tài khoản được xác nhận là của trẻ vị thành niên.
- Chúng tôi đang phát triển một bộ phân loại mới để phát hiện các dấu hiệu tinh tế hơn cho thấy người dùng có thể chưa đủ tuổi.
- Chúng tôi đã tham gia Viện An toàn Trực tuyến Gia đình (FOSI) để tăng cường các nỗ lực trong lĩnh vực này.
Hướng tới tương lai
Chúng tôi sẽ tiếp tục xây dựng các biện pháp bảo vệ và an toàn mới để bảo vệ sức khỏe tinh thần người dùng, đồng thời không ngừng cải tiến các phương pháp đánh giá. Chúng tôi cam kết công khai các phương pháp và kết quả của mình một cách minh bạch và hợp tác với các bên trong ngành để cải thiện hành vi của các công cụ AI trong các lĩnh vực này.
Nếu bạn có phản hồi về cách Claude xử lý các cuộc trò chuyện này, vui lòng liên hệ với chúng tôi qua usersafety@anthropic.com hoặc sử dụng các biểu tượng cảm xúc “ngón tay cái” trong Claude.ai.
Chú thích
- Ở cuối mỗi phản hồi trên Claude.ai có tùy chọn gửi phản hồi cho chúng tôi thông qua nút “ngón tay cái lên” hoặc “ngón tay cái xuống”. Điều này chia sẻ cuộc trò chuyện với Anthropic; chúng tôi không sử dụng Claude.ai cho mục đích đào tạo hoặc nghiên cứu khác.
- Tính năng “prefilling” chỉ khả dụng qua API, vì các nhà phát triển thường cần kiểm soát chi tiết hơn hành vi của mô hình, nhưng không thể sử dụng trên Claude.ai.
- Trong các kiểm toán hành vi tự động, chúng tôi cung cấp cho một mô hình Claude (người kiểm toán) hàng trăm kịch bản hội thoại khác nhau mà chúng tôi nghi ngờ mô hình có thể thể hiện hành vi nguy hiểm hoặc bất ngờ, và chấm điểm mỗi cuộc trò chuyện dựa trên khoảng hai chục hành vi của Claude (xem trang 69 trong thẻ hệ thống Claude Opus 4.5). Không phải mọi cuộc trò chuyện đều cho phép Claude thể hiện mọi hành vi. Ví dụ, việc khuyến khích ảo tưởng của người dùng đòi hỏi người dùng phải thể hiện hành vi ảo tưởng trước tiên, nhưng sự xu nịnh có thể xuất hiện trong nhiều ngữ cảnh khác nhau. Do chúng tôi sử dụng cùng một mẫu số (tổng số cuộc trò chuyện) khi chấm điểm từng hành vi, điểm số có thể thay đổi đáng kể. Vì lý do này, các bài kiểm tra này hữu ích nhất để so sánh sự tiến bộ giữa các mô hình Claude, chứ không phải giữa các hành vi.
- Bản phát hành công khai bao gồm hơn 100 hướng dẫn khởi đầu và các chiều đo lường có thể tùy chỉnh, mặc dù nó chưa bao gồm bộ lọc thực tế mà chúng tôi sử dụng nội bộ để ngăn mô hình nhận ra chúng đang bị kiểm tra.
Link bài viết gốc
- Tags:
- Ai
- Dec 18, 2025
- Www.anthropic.com