Gemini 3.1 Flash-Lite- Được xây dựng cho trí thông minh ở quy mô lớn
Giới thiệu mô hình Gemini 3.1 Flash-Lite với khả năng tối ưu hóa trí thông minh vượt trội
- 4 min read

Gemini 3.1 Flash-Lite: Được xây dựng cho trí tuệ nhân tạo ở quy mô lớn
Hôm nay, chúng tôi giới thiệu Gemini 3.1 Flash-Lite, mô hình thuộc dòng Gemini 3 nhanh nhất và tiết kiệm chi phí nhất của chúng tôi cho đến nay. Được thiết kế dành riêng cho các tác vụ khối lượng lớn của nhà phát triển, 3.1 Flash-Lite mang lại chất lượng vượt trội so với mức giá và phân khúc mô hình của nó.
Kể từ hôm nay, 3.1 Flash-Lite đã bắt đầu được ra mắt dưới dạng bản thử nghiệm cho các nhà phát triển thông qua Gemini API trong Google AI Studio và cho các doanh nghiệp thông qua Vertex AI.
Hiệu quả chi phí mà không cần đánh đổi
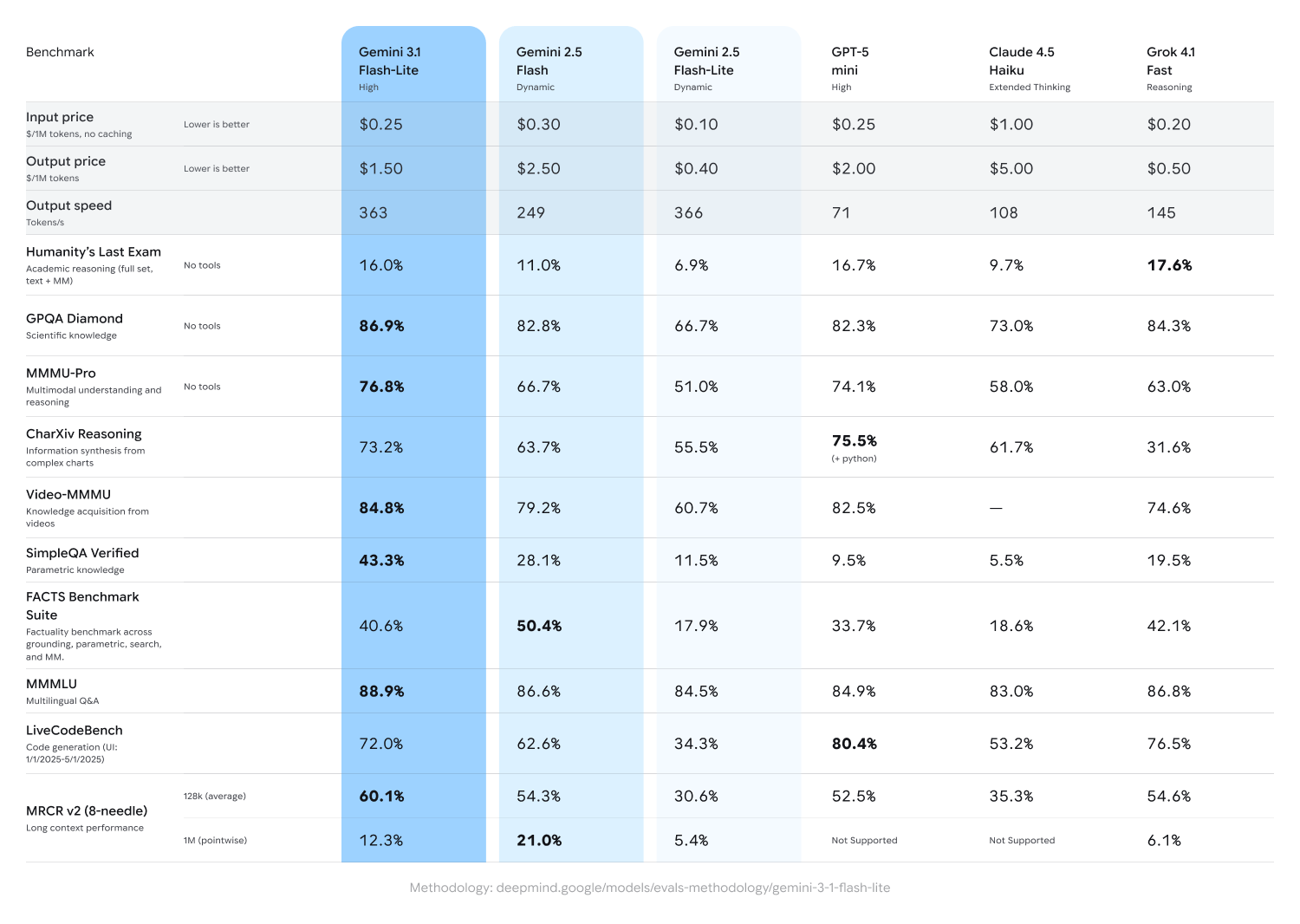
Với mức giá chỉ 0,25 USD/1 triệu token đầu vào và 1,50 USD/1 triệu token đầu ra, 3.1 Flash-Lite mang lại hiệu suất nâng cao với chi phí chỉ bằng một phần nhỏ so với các mô hình lớn hơn. Theo bảng xếp hạng Artificial Analysis, mô hình này vượt trội hơn bản 2.5 Flash với thời gian phản hồi token đầu tiên nhanh hơn gấp 2,5 lần và tốc độ đầu ra tăng 45%, trong khi vẫn duy trì chất lượng tương đương hoặc tốt hơn. Độ trễ thấp này là yếu tố cần thiết cho các quy trình làm việc tần suất cao, biến nó thành lựa chọn lý tưởng cho các nhà phát triển khi xây dựng những trải nghiệm phản hồi theo thời gian thực.

Gemini 3.1 Flash-Lite vượt trội hơn 2.5 Flash về tốc độ và chất lượng.
Gemini 3.1 Flash-Lite đạt điểm Elo ấn tượng là 1432 trên bảng xếp hạng Arena.ai và vượt qua các mô hình khác cùng phân khúc trong các tiêu chuẩn đánh giá về suy luận và hiểu đa phương thức, bao gồm 86,9% trên GPQA Diamond và 76,8% trên MMMU Pro — thậm chí vượt qua cả các mô hình Gemini lớn hơn từ thế hệ trước như 2.5 Flash.
Trí tuệ thích ứng ở quy mô lớn cho nhà phát triển
Ngoài hiệu suất thô, Gemini 3.1 Flash-Lite được trang bị tiêu chuẩn các cấp độ suy nghĩ (thinking levels) trong AI Studio và Vertex AI. Điều này cung cấp cho các nhà phát triển khả năng kiểm soát và linh hoạt để chọn mức độ “suy nghĩ” của mô hình cho một tác vụ cụ thể, vốn rất quan trọng để quản lý khối lượng công việc cường độ cao.
3.1 Flash-Lite có thể giải quyết các tác vụ ở quy mô lớn như dịch thuật khối lượng cao và kiểm duyệt nội dung — những lĩnh vực ưu tiên về chi phí. Đồng thời, nó cũng có thể xử lý các khối lượng công việc phức tạp hơn cần suy luận chuyên sâu, chẳng hạn như tạo giao diện người dùng và bảng điều khiển, lập mô phỏng hoặc tuân thủ các hướng dẫn cụ thể.
Các ví dụ về khả năng ứng dụng:
- Tạo danh mục thương mại điện tử: 3.1 Flash-Lite tự động lấp đầy khung dây e-commerce với hàng trăm sản phẩm thuộc các danh mục khác nhau.
- Bảng điều khiển thời tiết: 3.1 Flash-Lite có thể tạo bảng điều khiển thời tiết động trong thời gian thực, sử dụng dự báo trực tiếp và dữ liệu lịch sử.
- Tác nhân SaaS: 3.1 Flash-Lite tạo ra một tác nhân SaaS có khả năng thực hiện các tác vụ đa bước linh hoạt cho doanh nghiệp.
- Sắp xếp hình ảnh: Phân tích và phân loại nhanh chóng số lượng lớn nội dung hình ảnh.
Các nhà phát triển truy cập sớm trên AI Studio và Vertex AI, cùng với các công ty như Latitude, Cartwheel và Whering, hiện đang sử dụng 3.1 Flash-Lite để giải quyết các vấn đề phức tạp ở quy mô lớn. Những người thử nghiệm sớm đánh giá cao khả năng hiệu quả và tư duy của 3.1 Flash-Lite, cho rằng nó có thể xử lý các đầu vào phức tạp với độ chính xác như các mô hình cấp cao hơn, cộng với khả năng tuân thủ hướng dẫn và duy trì sự nhất quán.
Chúng tôi rất mong chờ được chứng kiến những sản phẩm mà bạn sẽ tạo ra với 3.1 Flash-Lite và các mô hình còn lại trong dòng Gemini 3.
Link bài viết gốc
- Tags:
- Ai
- 12 March 2026
- Blog.google