Gemma 4
Từng byte một, những mô hình mở có khả năng nhất
- 9 min read

Gemma 4: Những mô hình mở mạnh mẽ nhất hiện nay
Tác giả: Clement Farabet, Olivier Lacombe
Ngày đăng: 02 tháng 4, 2026

Hôm nay, chúng tôi xin giới thiệu Gemma 4 — những mô hình mở thông minh nhất của chúng tôi cho đến nay. Được thiết kế chuyên biệt cho khả năng suy luận nâng cao và các luồng công việc tự trị (agentic workflows), Gemma 4 mang lại mức độ trí thông minh trên mỗi tham số chưa từng có. Bước đột phá này dựa trên động lực to lớn từ cộng đồng: kể từ khi ra mắt thế hệ đầu tiên, các nhà phát triển đã tải xuống Gemma hơn 400 triệu lần, tạo nên một “vũ trụ Gemma” (Gemmaverse) sôi động với hơn 100.000 biến thể. Chúng tôi đã lắng nghe kỹ lưỡng nhu cầu của những nhà đổi mới để tiếp tục đẩy xa ranh giới của AI, và Gemma 4 chính là câu trả lời: những khả năng đột phá được cung cấp rộng rãi theo giấy phép Apache 2.0.
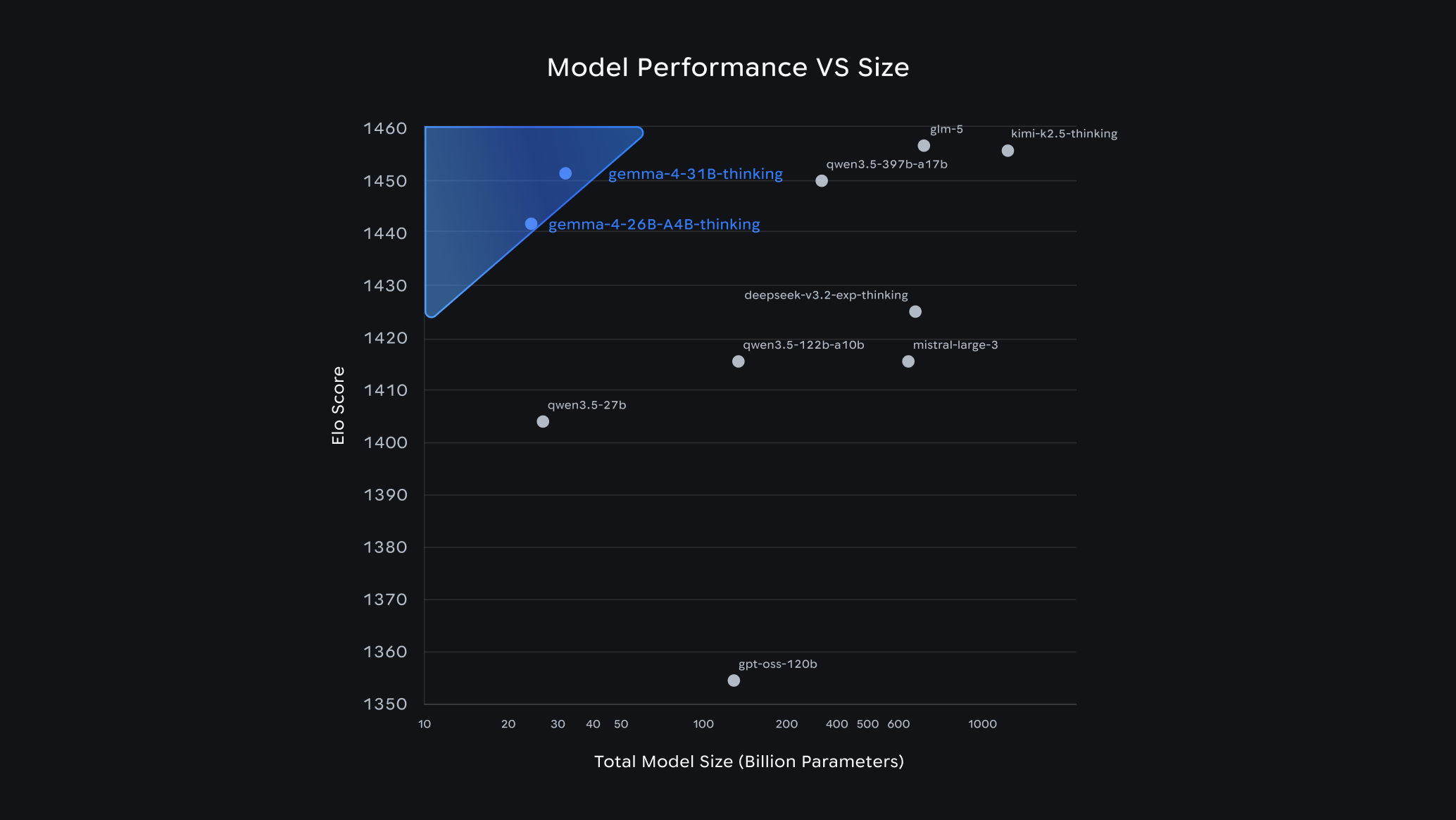 Hiệu suất mô hình mở so với kích thước trên Arena.ai tính đến ngày 1/4.
Hiệu suất mô hình mở so với kích thước trên Arena.ai tính đến ngày 1/4.
Được xây dựng từ cùng một công trình nghiên cứu và công nghệ đẳng cấp thế giới như Gemini 3, Gemma 4 là dòng mô hình mạnh mẽ nhất mà bạn có thể chạy trên phần cứng của riêng mình. Chúng bổ trợ cho các mô hình Gemini, mang đến cho các nhà phát triển sự kết hợp mạnh mẽ nhất trong ngành giữa các công cụ mở và công cụ độc quyền.
Khả năng dẫn đầu ngành và AI ưu tiên thiết bị di động
Chúng tôi phát hành Gemma 4 với bốn kích thước linh hoạt: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (MoE) và 31B Dense. Toàn bộ dòng mô hình này không chỉ dừng lại ở việc trò chuyện đơn thuần mà còn xử lý được các logic phức tạp và luồng công việc tự trị.
Các mô hình lớn hơn mang lại hiệu suất tiên tiến so với kích thước của chúng; trong đó mô hình 31B hiện đứng thứ 3 trong số các mô hình mở trên thế giới theo bảng xếp hạng văn bản tiêu chuẩn Arena AI, và mô hình 26B đứng vị trí thứ 6. Tại đây, Gemma 4 vượt mặt cả những mô hình có kích thước lớn gấp 20 lần. Đối với các nhà phát triển, mức độ trí thông minh trên mỗi tham số này có nghĩa là đạt được khả năng cấp độ tiên phong với chi phí phần cứng thấp hơn đáng kể.
Đối với các thiết bị đầu cuối (edge), các mô hình E2B và E4B định nghĩa lại tiện ích trên thiết bị, ưu tiên khả năng đa phương thức, xử lý độ trễ thấp và tích hợp hệ sinh thái mượt mà thay vì chỉ tập trung vào số lượng tham số thuần túy.
Mạnh mẽ, dễ tiếp cận và cởi mở
Để thúc đẩy thế hệ nghiên cứu và sản phẩm tiên phong tiếp theo, chúng tôi đã thiết kế kích thước các mô hình Gemma 4 để chạy và tinh chỉnh (fine-tune) hiệu quả trên nhiều loại phần cứng — từ hàng tỷ thiết bị Android trên toàn thế giới, GPU laptop, cho đến các máy trạm và bộ tăng tốc của nhà phát triển.
Bằng cách sử dụng các mô hình được tối ưu hóa cao này, bạn có thể tinh chỉnh Gemma 4 để đạt hiệu suất tối ưu cho các tác vụ cụ thể. Chúng tôi đã thấy những thành công đáng kinh ngạc; ví dụ, INSAIT đã tạo ra một mô hình ngôn ngữ tiên phong cho tiếng Bulgaria (BgGPT), và chúng tôi đã hợp tác với Đại học Yale trong dự án Cell2Sentence-Scale để khám phá các con đường mới cho liệu pháp điều trị ung thư.
Những điểm khiến Gemma 4 trở thành dòng mô hình mở mạnh mẽ nhất của chúng tôi:
- Suy luận nâng cao: Có khả năng lập kế hoạch nhiều bước và logic chuyên sâu, Gemma 4 cho thấy những cải tiến đáng kể trong các bài kiểm tra về toán học và tuân thủ hướng dẫn.
- Luồng công việc tự trị (Agentic workflows): Hỗ trợ gốc cho gọi hàm (function-calling), xuất dữ liệu JSON cấu trúc và hướng dẫn hệ thống gốc, cho phép bạn xây dựng các tác tử tự trị có thể tương tác với các công cụ/API khác nhau và thực thi quy trình làm việc một cách đáng tin cậy.
- Tạo mã nguồn (Code generation): Gemma 4 hỗ trợ tạo code ngoại tuyến chất lượng cao, biến máy trạm của bạn thành một trợ lý lập trình AI cục bộ.
- Thị giác và âm thanh: Tất cả các mô hình đều xử lý video và hình ảnh một cách tự nhiên, hỗ trợ độ phân giải thay đổi và xuất sắc trong các tác vụ thị giác như OCR và hiểu biểu đồ. Ngoài ra, các mô hình E2B và E4B còn hỗ trợ đầu vào âm thanh gốc để nhận dạng và hiểu tiếng nói.
- Ngữ cảnh dài hơn: Xử lý nội dung dài một cách mượt mà. Các mô hình cho thiết bị đầu cuối có cửa sổ ngữ cảnh 128K, trong khi các mô hình lớn hơn cung cấp lên đến 256K, cho phép bạn đưa toàn bộ kho lưu trữ mã nguồn hoặc tài liệu dài vào một câu lệnh duy nhất.
- Hơn 140 ngôn ngữ: Được huấn luyện gốc trên hơn 140 ngôn ngữ, giúp các nhà phát triển xây dựng các ứng dụng hiệu suất cao, bao trùm cho khán giả toàn cầu.
Các mô hình linh hoạt cho phần cứng đa dạng
Chúng tôi cung cấp trọng số mô hình Gemma 4 với các kích thước được tùy chỉnh cho từng loại phần cứng và trường hợp sử dụng:
Mô hình 26B và 31B: Trí thông minh tiên phong, chạy ngoại tuyến trên máy tính cá nhân
Được tối ưu hóa để cung cấp khả năng suy luận hiện đại trên phần cứng dễ tiếp cận. Trọng số bfloat16 chưa lượng tử hóa khớp hiệu quả trên một GPU NVIDIA H100 80GB. Đối với các thiết lập cục bộ, các phiên bản lượng tử hóa chạy trực tiếp trên GPU tiêu dùng để cung cấp sức mạnh cho IDE, trợ lý lập trình và luồng công việc tự trị.
- 26B MoE: Tập trung vào độ trễ, chỉ kích hoạt 3,8 tỷ tham số trong tổng số khi suy luận để đạt tốc độ tạo token cực nhanh.
- 31B Dense: Tối đa hóa chất lượng thô và cung cấp nền tảng mạnh mẽ để tinh chỉnh.
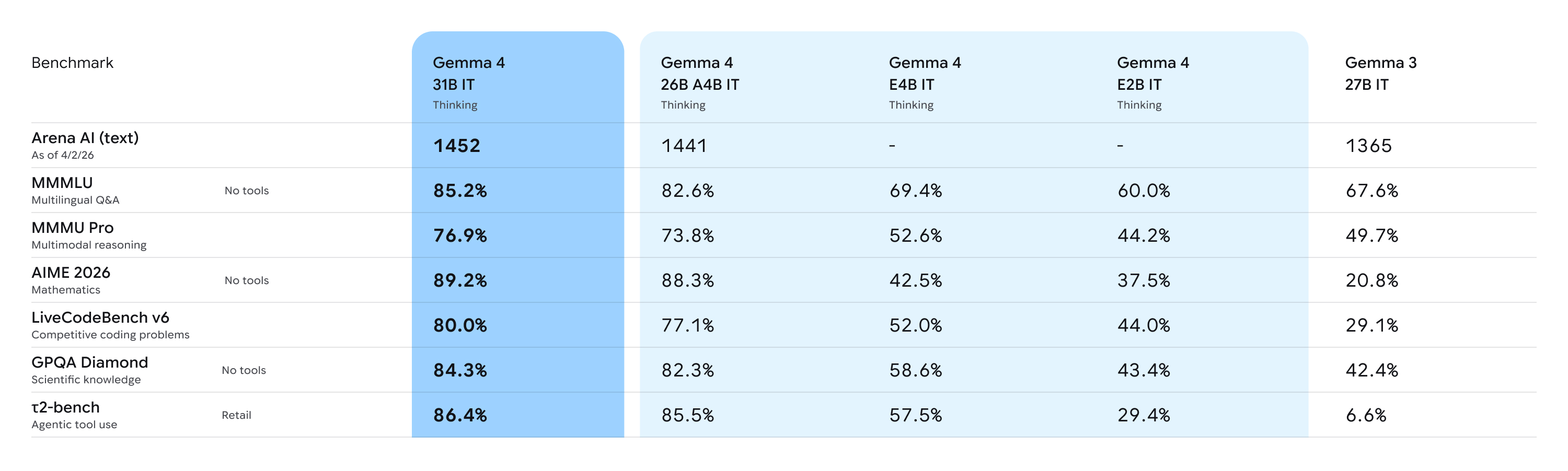 Các mô hình này được đánh giá dựa trên một tập hợp lớn các bộ dữ liệu và chỉ số khác nhau để bao quát các khía cạnh của việc tạo văn bản. Xem thêm các bài kiểm tra trong thẻ mô hình của chúng tôi.
Các mô hình này được đánh giá dựa trên một tập hợp lớn các bộ dữ liệu và chỉ số khác nhau để bao quát các khía cạnh của việc tạo văn bản. Xem thêm các bài kiểm tra trong thẻ mô hình của chúng tôi.
Mô hình E2B và E4B: Cấp độ trí thông minh mới cho thiết bị di động và IoT
Được thiết kế từ đầu để đạt hiệu quả tối đa về tính toán và bộ nhớ, các mô hình này kích hoạt dấu chân tham số hiệu dụng là 2 tỷ và 4 tỷ trong khi suy luận để bảo tồn RAM và thời lượng pin. Hợp tác chặt chẽ với đội ngũ Google Pixel và các đối tác phần cứng như Qualcomm và MediaTek, các mô hình đa phương thức này chạy hoàn toàn ngoại tuyến với độ trễ gần như bằng không trên các thiết bị như điện thoại, Raspberry Pi và NVIDIA Jetson Orin Nano. Các nhà phát triển Android hiện có thể thử nghiệm các luồng tự trị trong AICore Developer Preview để tương thích với Gemini Nano 4.
Giấy phép nguồn mở
Chúng tôi đã lắng nghe phản hồi của các bạn. Việc xây dựng tương lai của AI đòi hỏi một cách tiếp cận cộng tác, và chúng tôi tin vào việc trao quyền cho hệ sinh thái nhà phát triển mà không có các rào cản hạn chế. Đó là lý do tại sao Gemma 4 được phát hành theo giấy phép Apache 2.0 cho phép sử dụng thương mại.
Giấy phép nguồn mở này cung cấp nền tảng cho sự linh hoạt hoàn toàn của nhà phát triển và chủ quyền kỹ thuật số; trao cho bạn quyền kiểm soát hoàn toàn đối với dữ liệu, cơ sở hạ tầng và mô hình. Nó cho phép bạn xây dựng tự do và triển khai an toàn trong bất kỳ môi trường nào, dù là tại chỗ (on-premises) hay trên đám mây.
“Việc phát hành Gemma 4 theo giấy phép Apache 2.0 là một cột mốc lớn. Chúng tôi vô cùng hào hứng khi hỗ trợ dòng mô hình Gemma 4 trên Hugging Face ngay từ ngày đầu ra mắt.”
— Clément Delangue, đồng sáng lập và CEO của Hugging Face
Xây dựng trên nền tảng tin cậy và an toàn
Các mô hình này trải qua các giao thức bảo mật cơ sở hạ tầng nghiêm ngặt tương tự như các mô hình độc quyền của chúng tôi. Bằng cách chọn Gemma 4, các doanh nghiệp và tổ chức chủ quyền sẽ có được một nền tảng minh bạch, đáng tin cậy, cung cấp khả năng tiên tiến trong khi đáp ứng các tiêu chuẩn cao nhất về bảo mật và độ tin cậy.
Hệ sinh thái đa dạng
- Bắt đầu thử nghiệm trong vài giây: Truy cập ngay Gemma 4 trong Google AI Studio (31B và 26B MoE) hoặc trong Google AI Edge Gallery (E4B và E2B). Đối với phát triển Android, hãy sử dụng nó để cung cấp sức mạnh cho Chế độ Tác tử (Agent Mode) trong Android Studio và xây dựng ứng dụng thực tế với ML Kit GenAI Prompt API.
- Sử dụng các công cụ yêu thích: Hỗ trợ ngay từ ngày đầu cho Hugging Face (Transformers, TRL, Transformers.js, Candle), LiteRT-LM, vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM và NeMo, LM Studio, Unsloth, SGLang, Cactus, Baseten, Docker, MaxText, Tunix, Keras.
- Tải xuống mô hình: Lấy trọng số mô hình từ Hugging Face, Kaggle hoặc Ollama.
- Tùy chỉnh theo nhu cầu: Huấn luyện và điều chỉnh mô hình bằng nền tảng bạn thích như Google Colab, Vertex AI hoặc thậm chí là GPU gaming của bạn.
- Mở rộng quy mô sản xuất trên Google Cloud: Triển khai thông qua Vertex AI, Cloud Run, GKE, Sovereign Cloud, phục vụ tăng tốc bằng TPU và các đảm bảo tuân thủ cao nhất cho các khối lượng công việc bị quản lý.
- Tăng tốc phát triển trên nhiều nền tảng phần cứng: Tối ưu hóa sẵn cho cơ sở hạ tầng NVIDIA (từ Jetson Orin Nano đến GPU Blackwell), tích hợp với GPU AMD qua ngăn xếp ROCm™ mã nguồn mở, hoặc triển khai trên TPU Trillium và Ironwood để đạt quy mô và hiệu quả khổng lồ.
- Thi thi đấu tạo tác động: Tham gia thử thách Gemma 4 Good Challenge trên Kaggle để xây dựng các sản phẩm tạo ra thay đổi tích cực và ý nghĩa cho thế giới.
Link bài viết gốc
- Tags:
- Ai
- April 2026
- Blog.google