Giới thiệu Gemma 4 12B- một mô hình đa phương thức thống nhất, không bộ mã hóa
Một mô hình đa phương thức thống nhất và không sử dụng bộ mã hóa
- 5 min read

Giới thiệu Gemma 4 12B: Mô hình đa phương thức thống nhất, không sử dụng bộ mã hóa
Ngày đăng: 03 tháng 6, 2026 Tác giả: Olivier Lacombe, Gus Martins
Gemma 4 12B được thiết kế để mang trí tuệ đa phương thức hiệu suất cao trực tiếp lên máy tính xách tay, kết hợp giữa hiệu suất tối ưu cho thiết bị di động và khả năng lập luận nâng cao.

Hôm nay, chúng tôi giới thiệu Gemma 4 12B, mô hình mới nhất được thiết kế để mang trí tuệ đa phương thức có khả năng tự vận hành (agentic) trực tiếp lên máy tính xách tay. Đóng vai trò là cầu nối giữa phiên bản E4B thân thiện với thiết bị cạnh (edge) và phiên bản 26B Mixture of Experts (MoE) tiên tiến hơn, Gemma 4 12B gói gọn những khả năng mạnh mẽ trong một mức chiếm dụng bộ nhớ thấp hơn. Đây cũng là mô hình kích thước trung bình đầu tiên của chúng tôi hỗ trợ đầu vào âm thanh nguyên bản.
Nhờ vào cộng đồng nhà phát triển, các mô hình Gemma 4 hiện đã vượt mốc 150 triệu lượt tải xuống. Các bạn đã xây dựng mọi thứ, từ cánh tay robot đeo tay để hỗ trợ vật lý đến hệ thống bảo mật AI cấp doanh nghiệp. Chúng tôi rất hào hứng muốn thấy bạn sẽ tạo ra điều gì với sự bổ sung mới nhất này.
Những điểm độc đáo của Gemma 4 12B:
- Kiến trúc thống nhất mới lạ: Không sử dụng các bộ mã hóa (encoders) đa phương thức. Các đầu vào hình ảnh và âm thanh được truyền trực tiếp vào khung xương LLM.
- Khả năng lập luận nâng cao: Hiệu suất benchmark gần tương đương với mô hình 26B, mở ra khả năng lập luận đa bước mạnh mẽ và các luồng công việc tự vận hành (agentic workflows).
- Sẵn sàng cho máy tính xách tay: Đủ nhỏ để chạy cục bộ chỉ với 16GB VRAM hoặc bộ nhớ thống nhất (unified memory).
- Mở và dễ tiếp cận: Được phát hành theo giấy phép Apache 2.0 với sự hỗ trợ rộng rãi trong hệ sinh thái nhà phát triển.
- Sẵn sàng cho Drafter: Gemma 4 12B được trang bị các trình phác thảo Dự đoán Đa Token (Multi-Token Prediction - MTP) để giảm độ trễ.
Tổng hợp lại, những tính năng này mang khả năng đa phương thức tiên tiến đến với các phần cứng thông dụng mà không làm hy sinh tốc độ hay khả năng lập luận. Hãy cùng tìm hiểu chi tiết cách Gemma 4 12B đạt được điều này.
Chạy các tác nhân (agents) hiện đại ngay trên máy cục bộ
Gemma 4 12B mang lại hiệu suất gần bằng mô hình 26B MoE lớn hơn trên các bài kiểm tra tiêu chuẩn, nhưng với mức chiếm dụng bộ nhớ tổng thể thấp hơn một nửa. Với khả năng chạy cục bộ trên các máy tính xách tay phổ thông có 16GB RAM, mô hình này mở ra những trải nghiệm đa phương thức và tự vận hành mạnh mẽ ngay trên thiết bị của bạn.
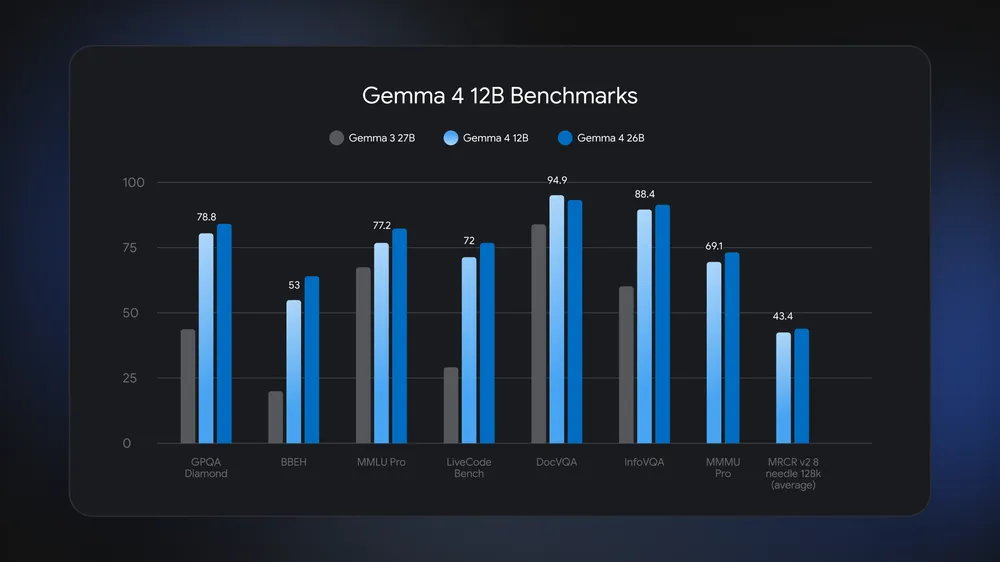
Trải nghiệm kiến trúc thống nhất với hiệu quả vượt trội
Điểm khiến Gemma 4 12B nổi bật là cách tiếp cận tinh gọn trong việc xử lý đầu vào hình ảnh và âm thanh. Các mô hình đa phương thức truyền thống thường dựa vào các bộ mã hóa riêng biệt để chuyển đổi hình ảnh và âm thanh trước khi chuyển các biểu diễn đó sang mô hình ngôn ngữ. Vì các bộ mã hóa tách biệt này gây thêm độ trễ và tăng sử dụng bộ nhớ, chúng tôi đã huấn luyện Gemma 4 12B với kiến trúc không bộ mã hóa (encoder-free) để tích hợp trực tiếp đầu vào âm thanh và hình ảnh.
Cách Gemma 4 12B xử lý đầu vào đa phương thức một cách nguyên bản:
- Hình ảnh: Chúng tôi thay thế bộ mã hóa hình ảnh của Gemma 4 bằng một mô-đun nhúng (embedding) nhẹ, bao gồm một phép nhân ma trận đơn lẻ, nhúng vị trí và chuẩn hóa. Điều này cho phép khung xương LLM trực tiếp đảm nhận việc xử lý hình ảnh.
- Âm thanh: Chúng tôi đơn giản hóa việc xử lý âm thanh hơn nữa bằng cách loại bỏ hoàn toàn bộ mã hóa âm thanh và chiếu tín hiệu âm thanh thô vào cùng một không gian chiều với các token văn bản.
Để biết chi tiết kỹ thuật, các nhà phát triển có thể tham khảo Hướng dẫn cho Nhà phát triển Gemma 4 12B.
Xem quy trình xử lý âm thanh nguyên bản trong thực tế: Hãy xem Gemma 4 12B chuyển soạn, định dạng và dịch các đầu vào giọng nói hoàn toàn ngoại tuyến bằng ứng dụng Google AI Edge Eloquent.
https://www.youtube.com/watch?v=Q5a7dAREbXM
Bắt đầu ngay hôm nay
- Tự mình trải nghiệm: Thử nghiệm nhanh chóng với vài cú nhấp chuột trong LM Studio, Ollama, Google AI Edge Gallery App, ứng dụng Google AI Edge Eloquent và LiteRT-LM CLI.
- Tải xuống trọng số (weights): Tải các bản checkpoint đã được huấn luyện trước và tinh chỉnh hướng dẫn trực tiếp từ Hugging Face và Kaggle.
- Tích hợp và học hỏi: Xem lại tài liệu dành cho nhà phát triển và sổ tay hướng dẫn bắt đầu nhanh.
- Sử dụng các công cụ phát triển yêu thích: Triển khai các đường ống suy luận cục bộ với Hugging Face Transformers, llama.cpp, MLX, SGLang, và vLLM, hoặc tinh chỉnh hiệu quả bằng Unsloth.
- Mở khóa phát triển Tác nhân với Gemma Skills: Để hỗ trợ các tác nhân xây dựng dựa trên những tiến bộ mới nhất của Gemma, chúng tôi phát hành Kho lưu trữ Kỹ năng (Skills Repository) chính thức. Đây là thư viện các kỹ năng được thiết kế đặc biệt để cho phép các tác nhân xây dựng với các mô hình Gemma.
- Triển khai theo cách của bạn: Thiết lập các điểm cuối (endpoints) trong môi trường sản xuất bằng Google Cloud thông qua Gemini Enterprise Agent Platform Model Garden, Cloud Run và GKE.
Link bài viết gốc
- Tags:
- Ai
- June 2026
- Blog.google